训练结果 on facebook:wav2letter
1.首先放几组结果
以下学习率均设成1.0
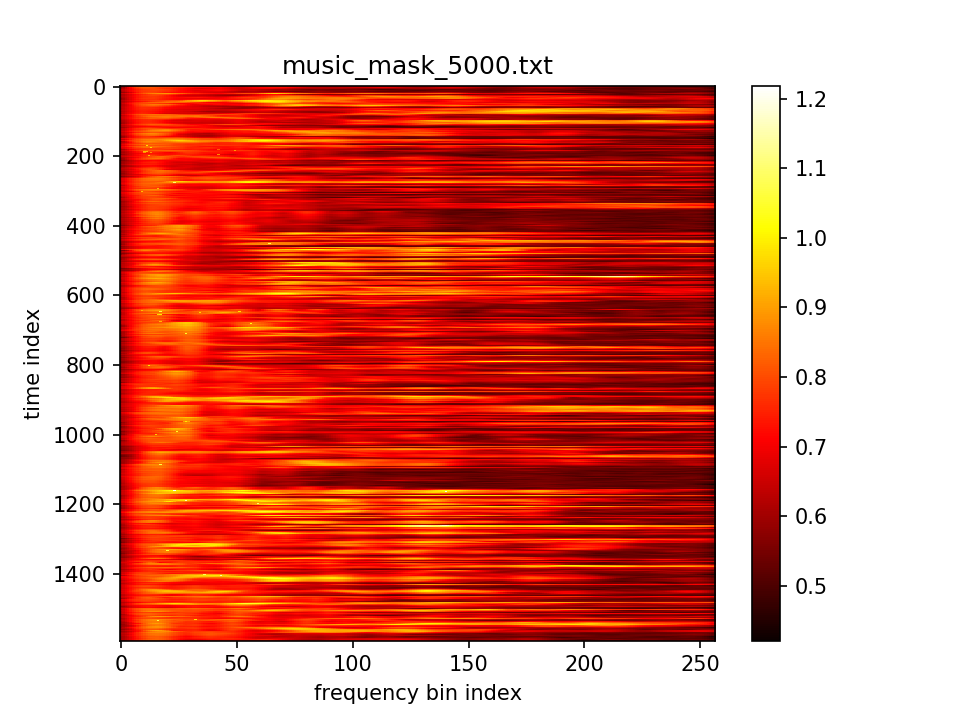
m初值5.0,λ=1.0,10000epoch,保持fft总值不变
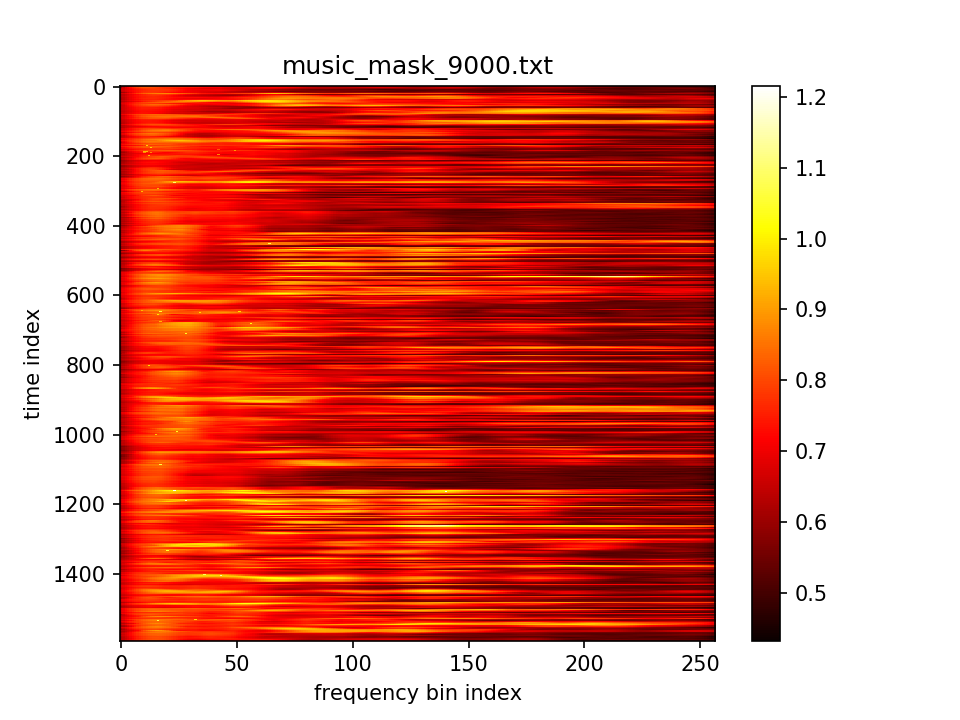
m初值5.0,λ乘在前一项=10e5,10000epoch,保持fft总值不变
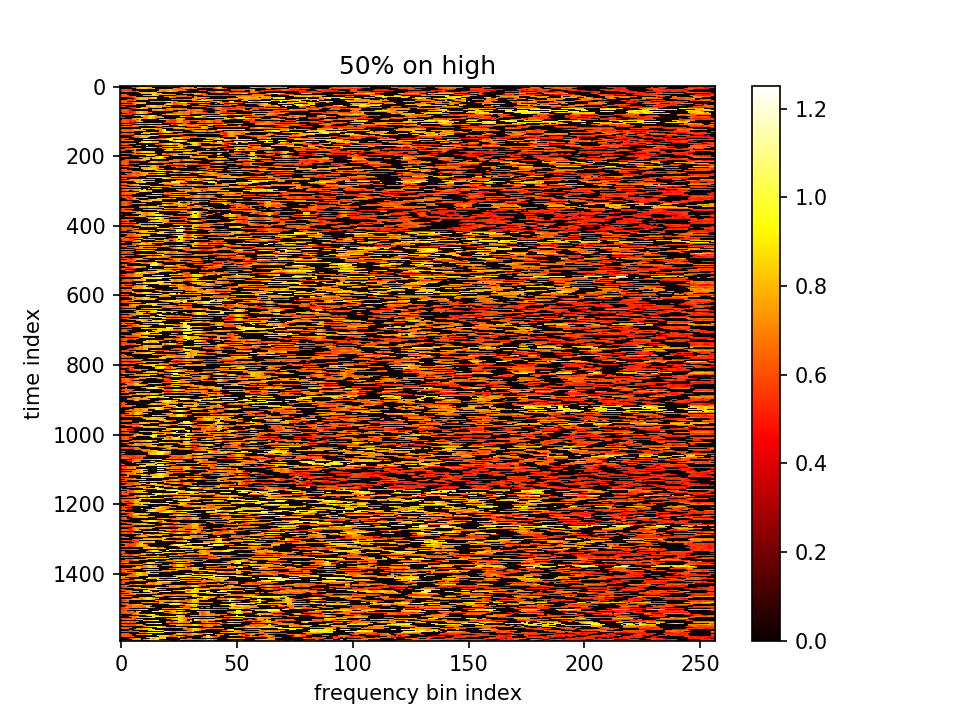
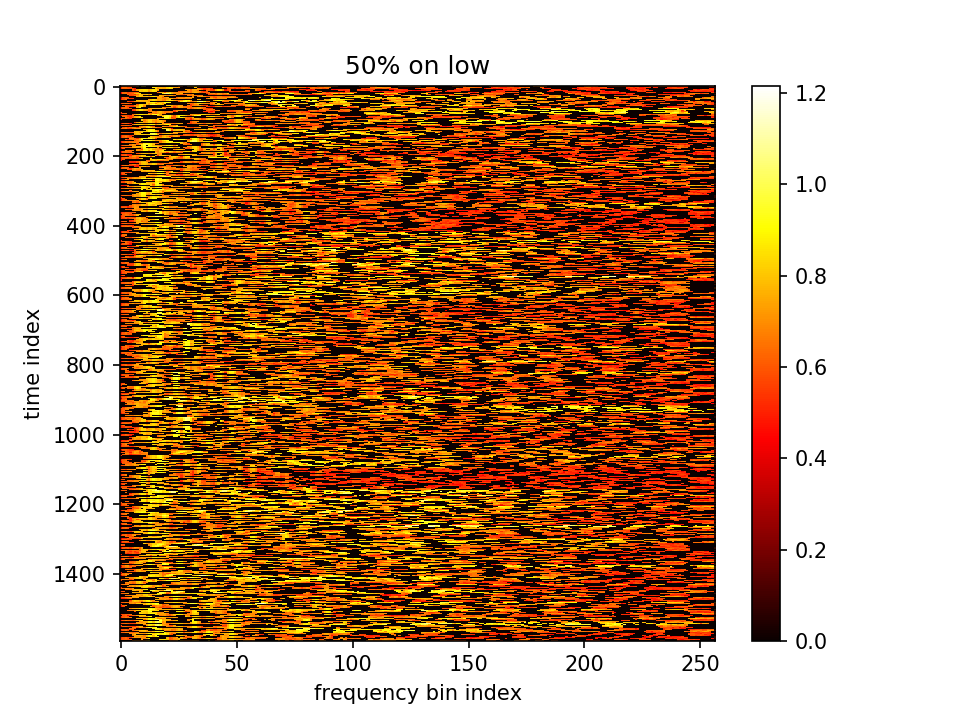
m初值5.0,λ乘在前一项=10e4,10000epoch,保持fft总值不变,m加relu抑制负值
2.按最初方法训练的结果
- m初值0.1,λ=0.1,5000epoch

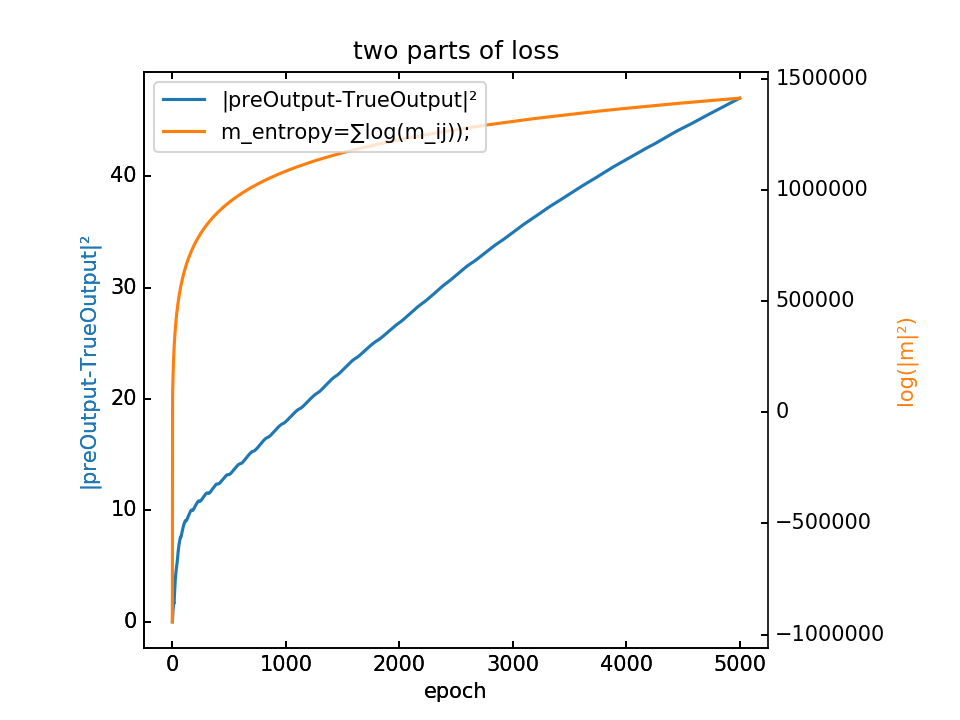
loss分为两部分,蓝-λ橙
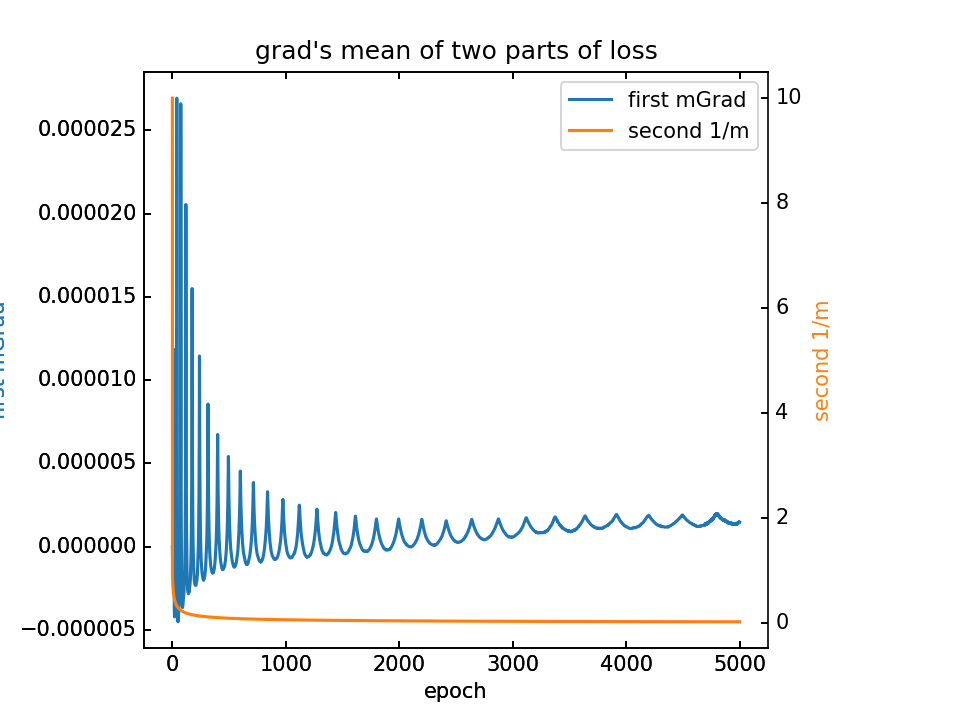
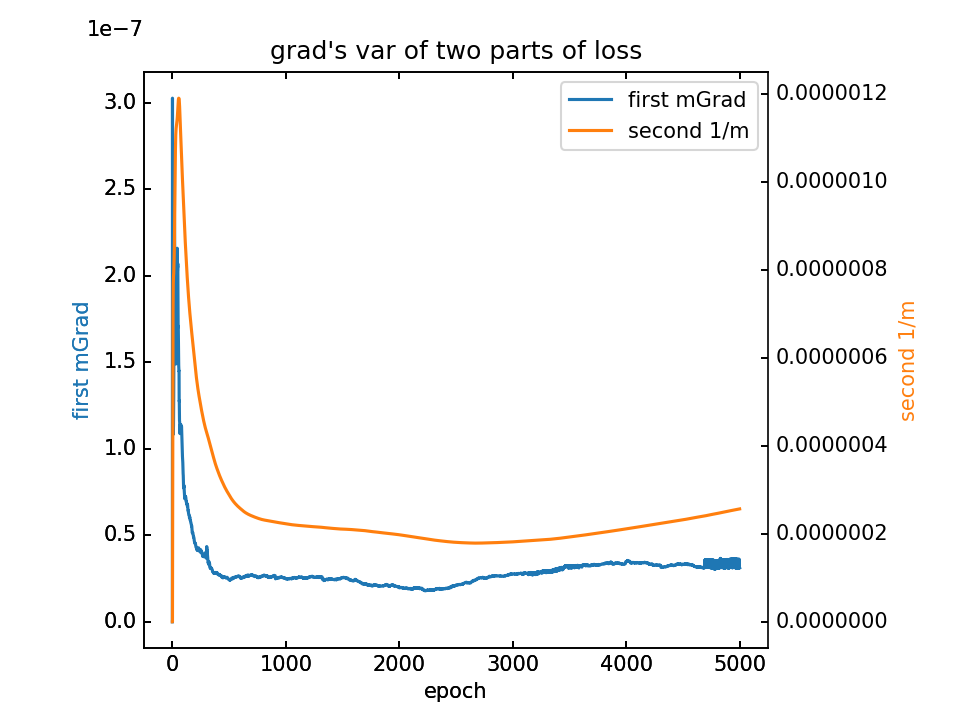
对m梯度分为两部分,蓝-λ橙。这里分别看梯度的平均值和方差
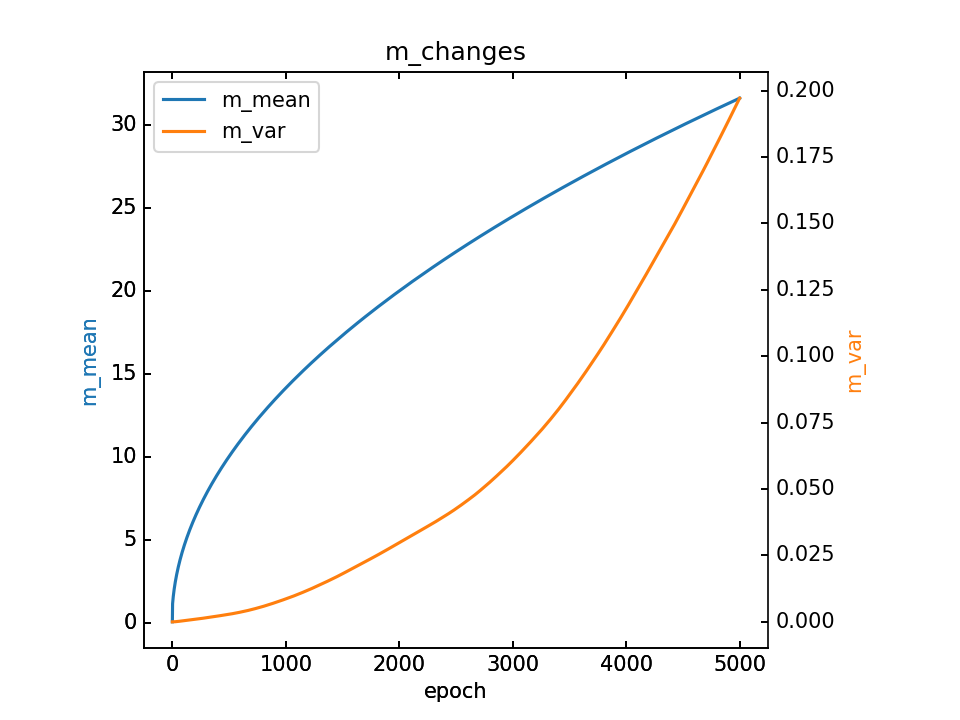
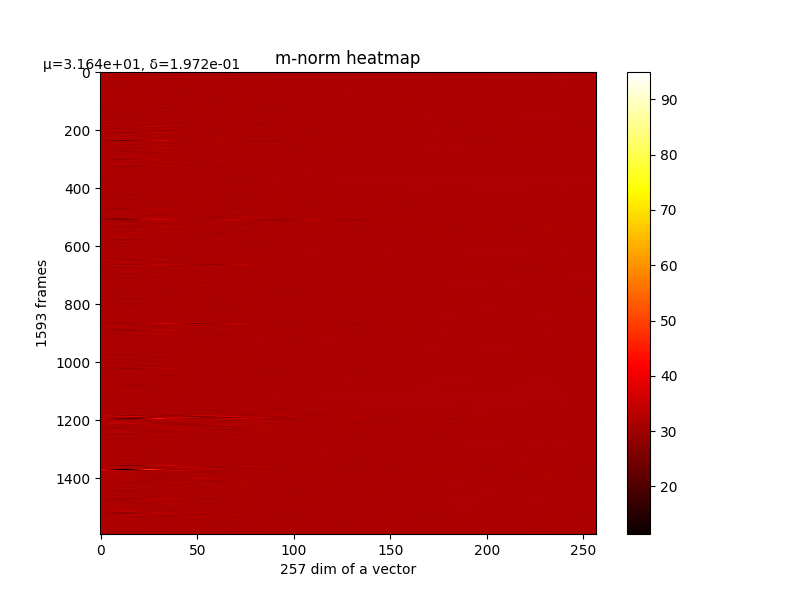
m的变化和最终m,详细
过程中经过模糊后的声音,eg. 第4000次:
最后输出在各个维度的分布:
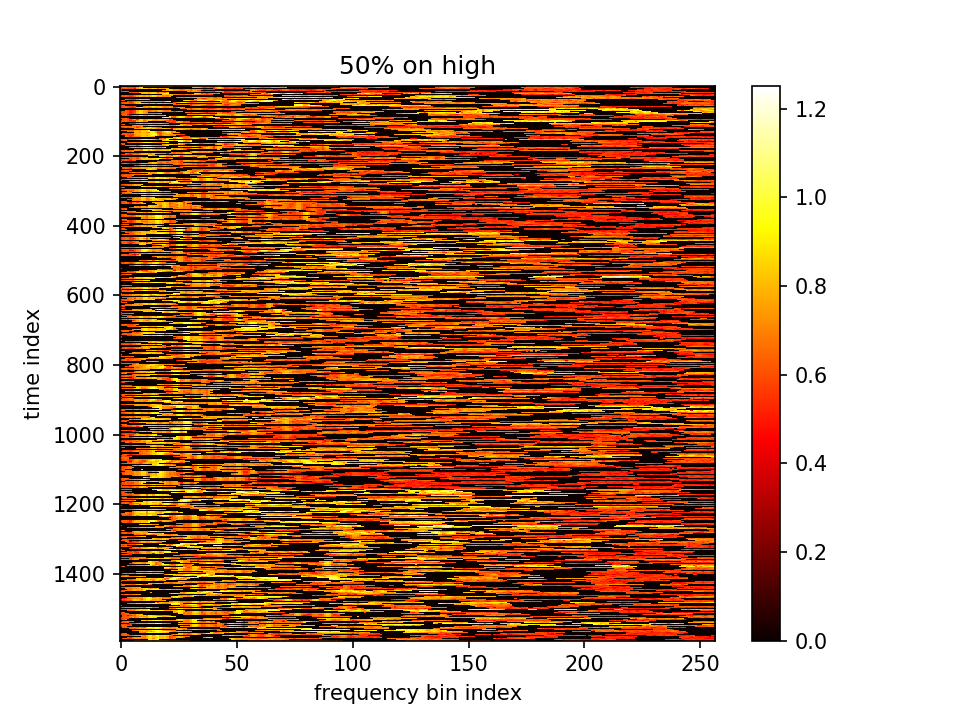
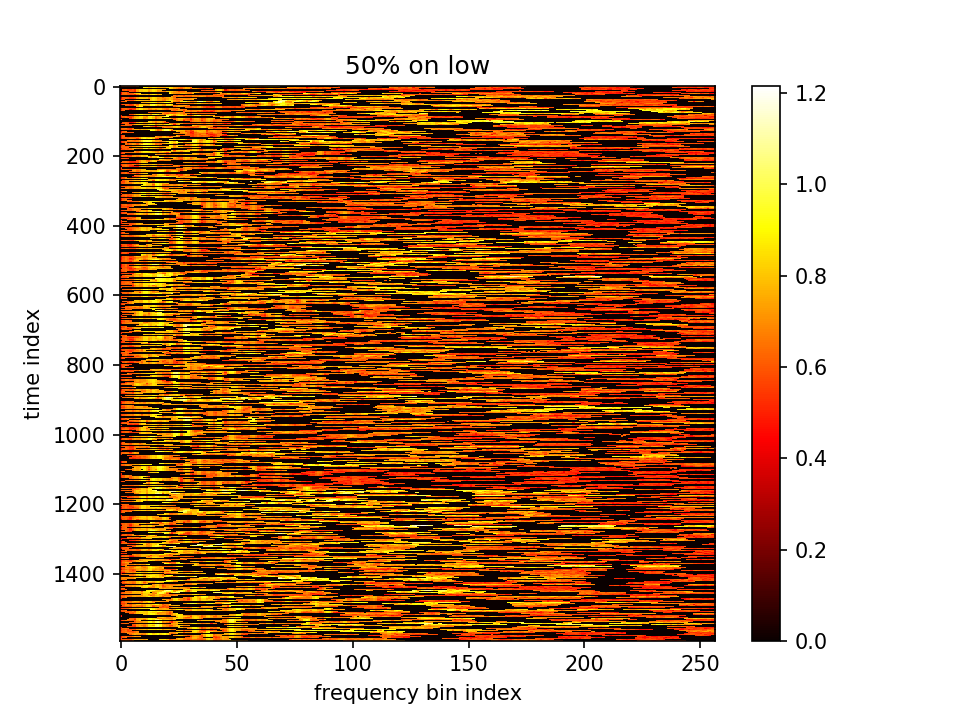
- m初值1.0,λ=0.01,10000epoch
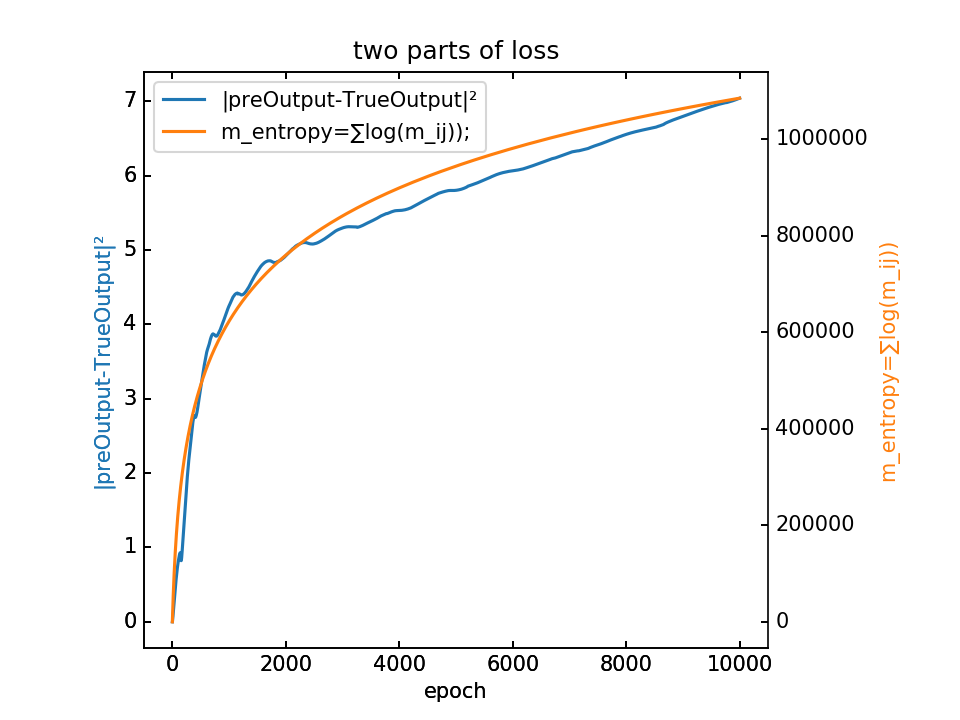
loss分为两部分,蓝-λ橙
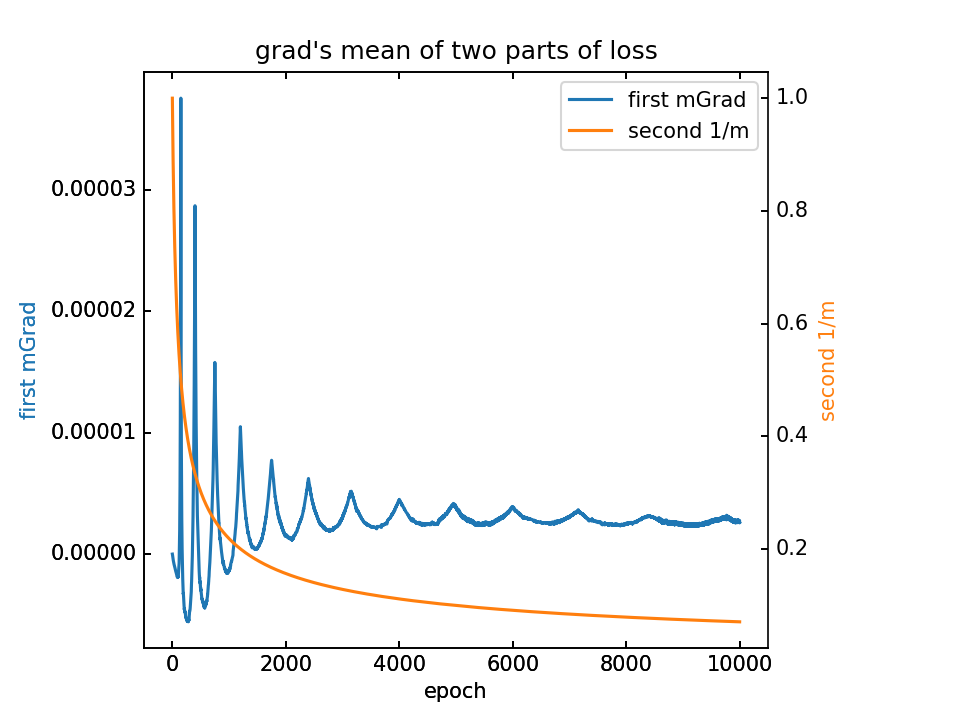
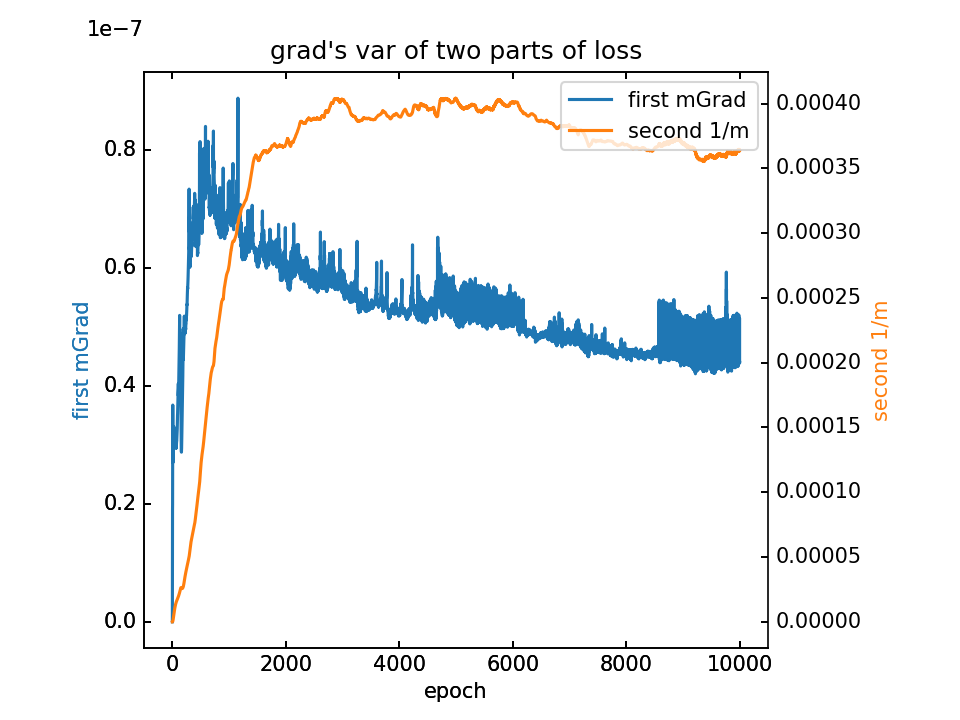
对m梯度分为两部分,蓝-λ橙。这里分别看梯度的平均值和方差
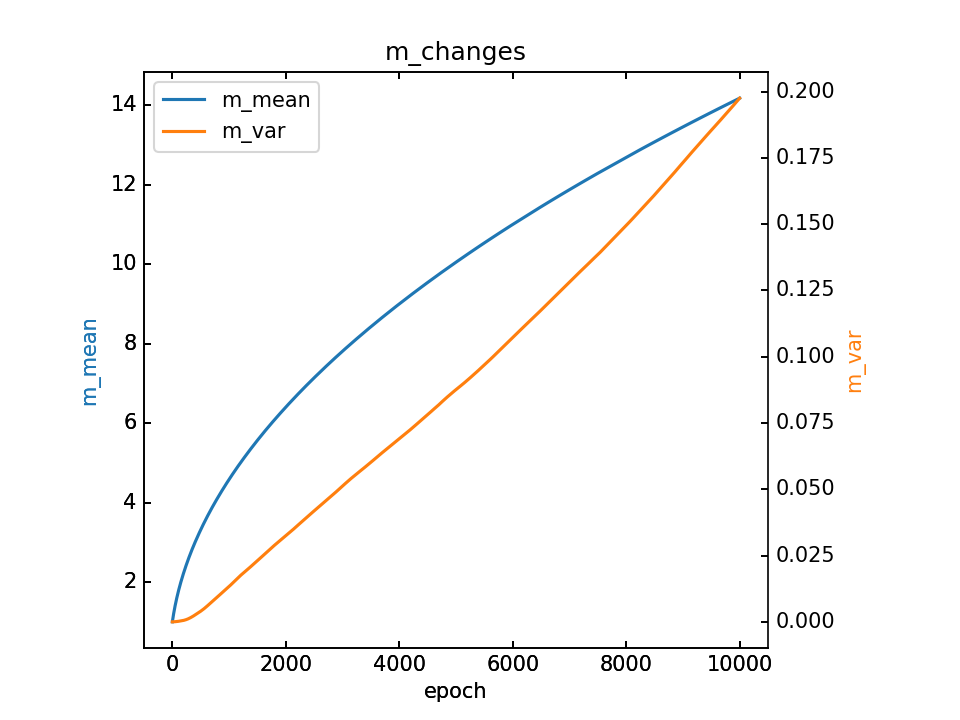

m的变化和最终m,详细
最后输出在各个维度的分布:
- m初值0.1,λ=0.000001,10000epoch
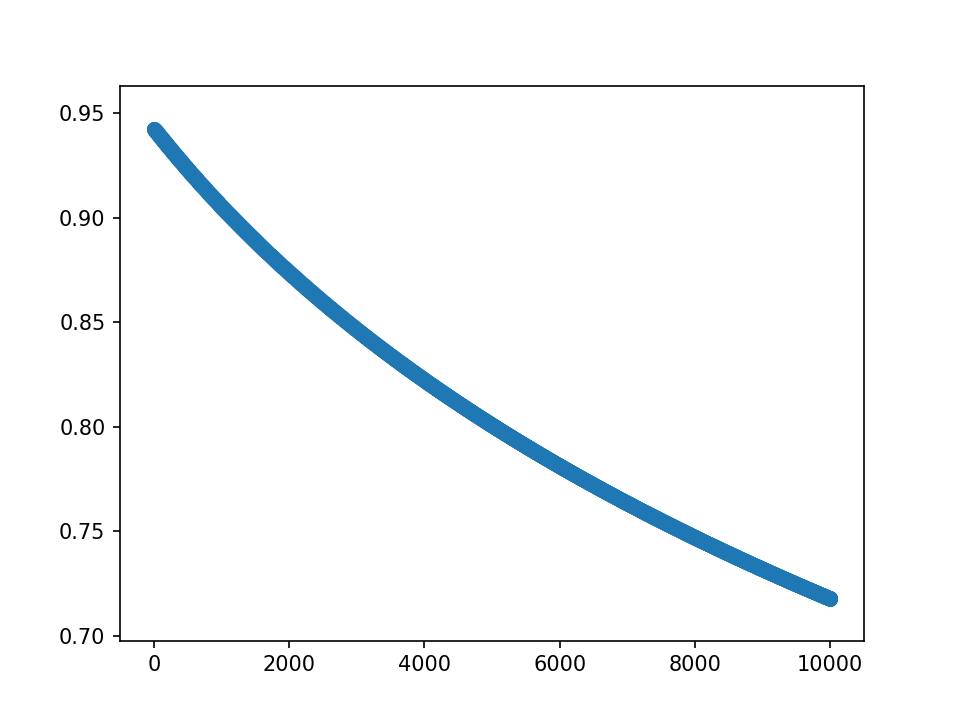
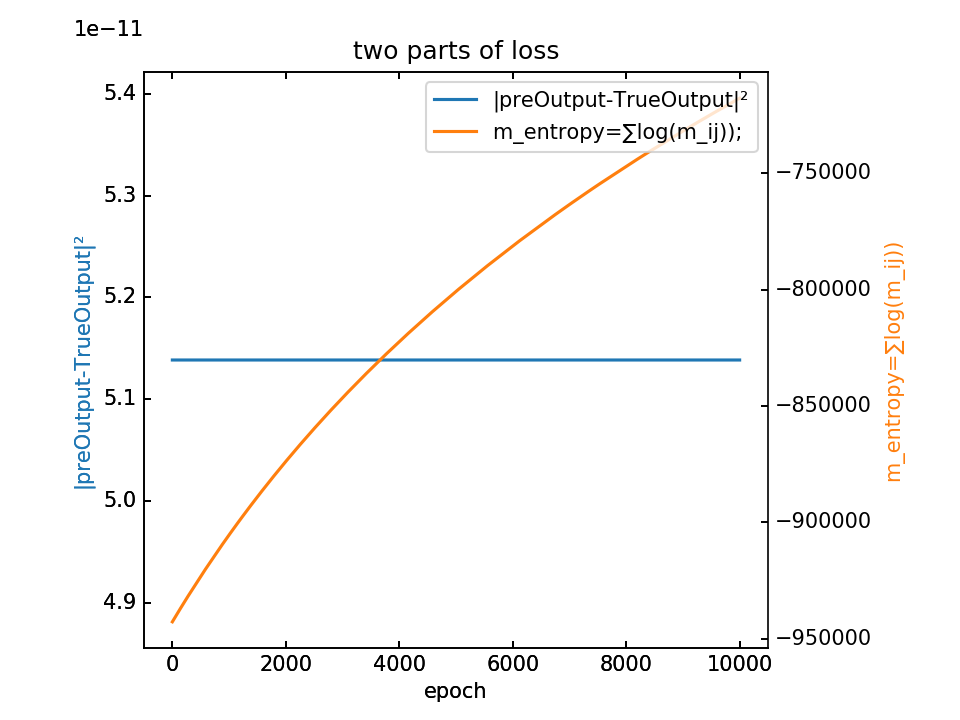
loss分为两部分,蓝-λ橙
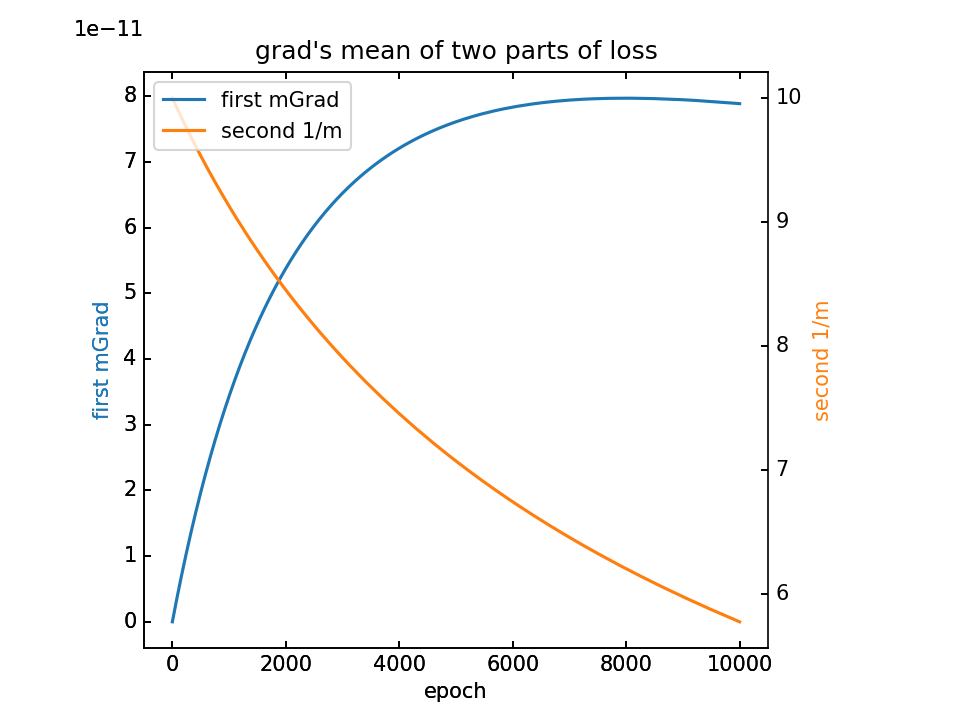
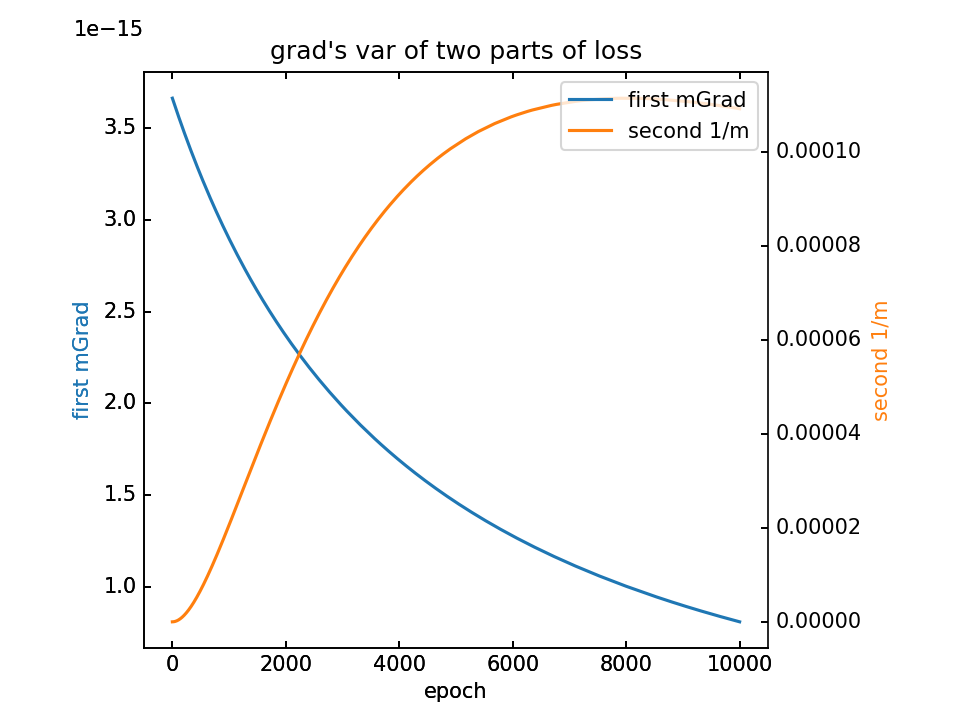
对m梯度分为两部分,蓝-λ橙。这里分别看梯度的平均值和方差
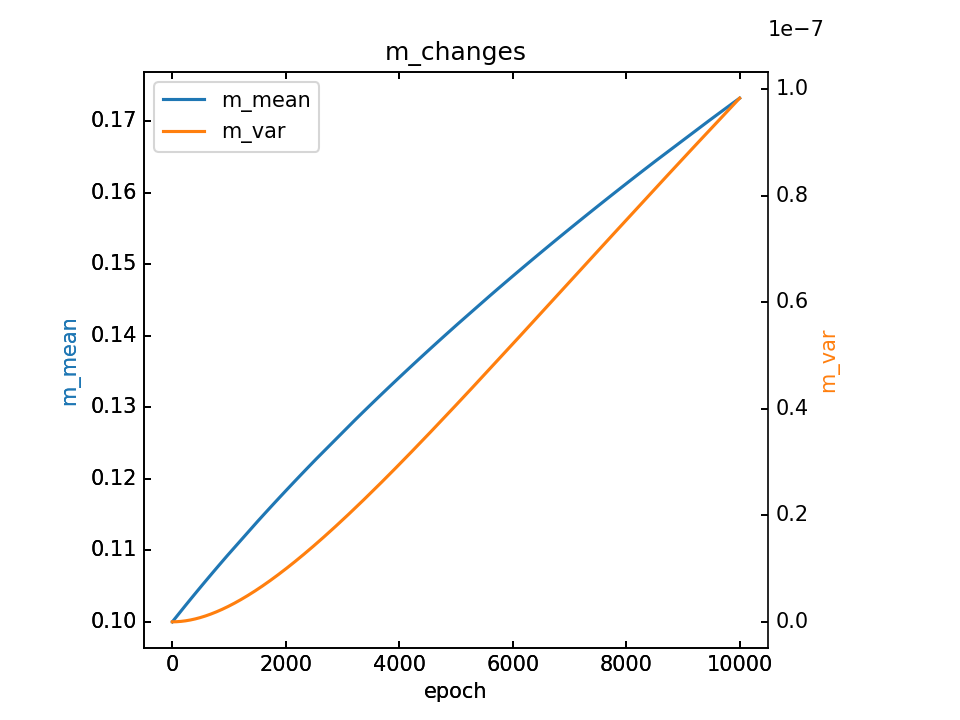

m的变化和最终m,详细
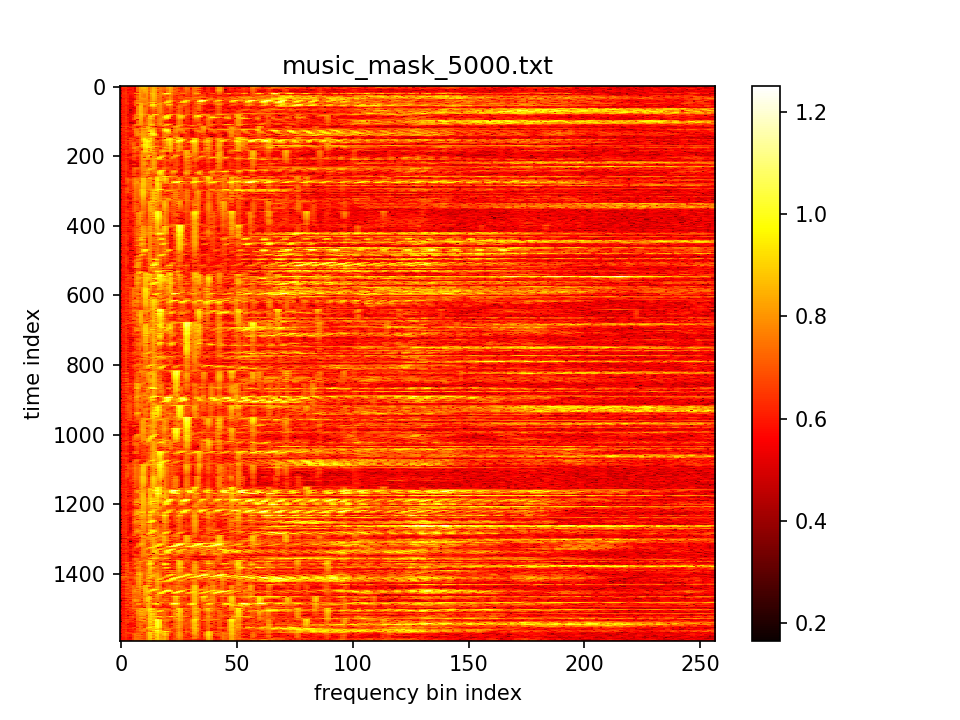

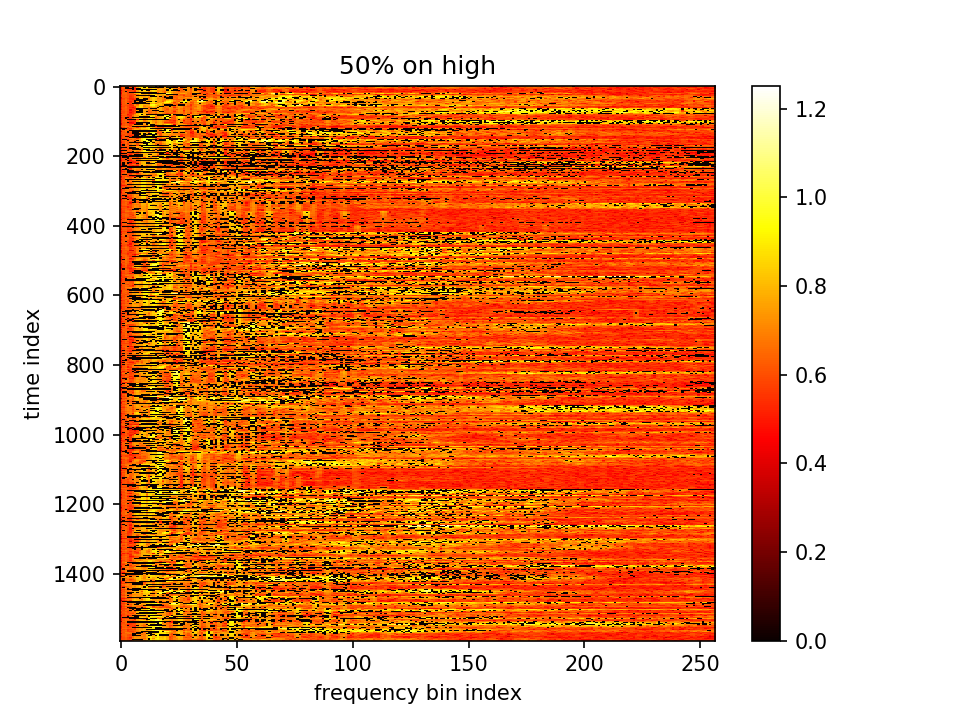
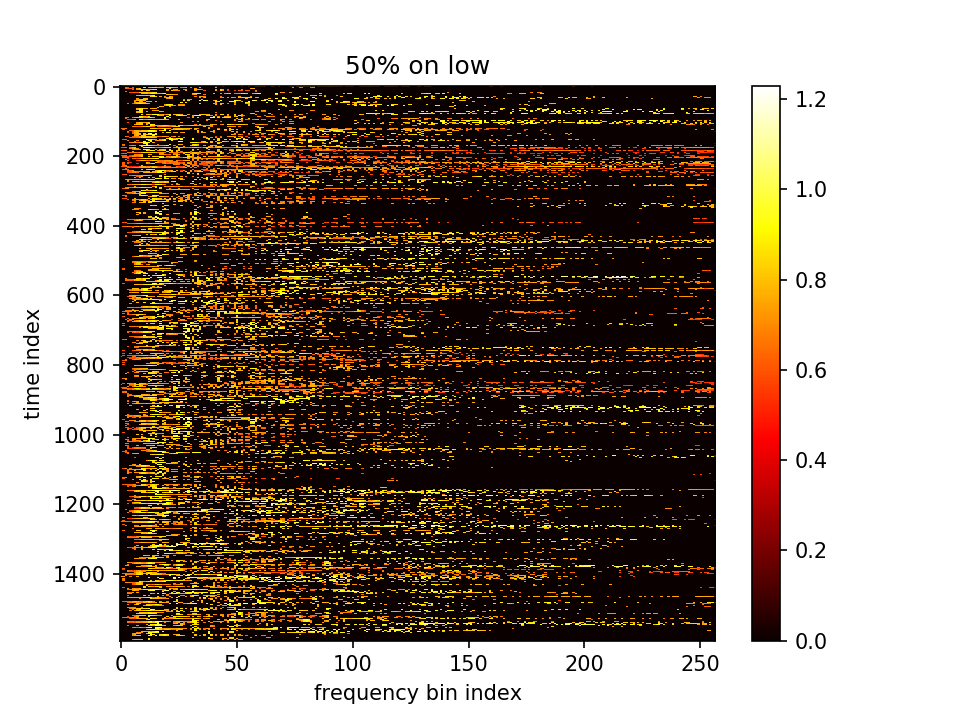
- m初值1.0,λ=10.0,10000epoch

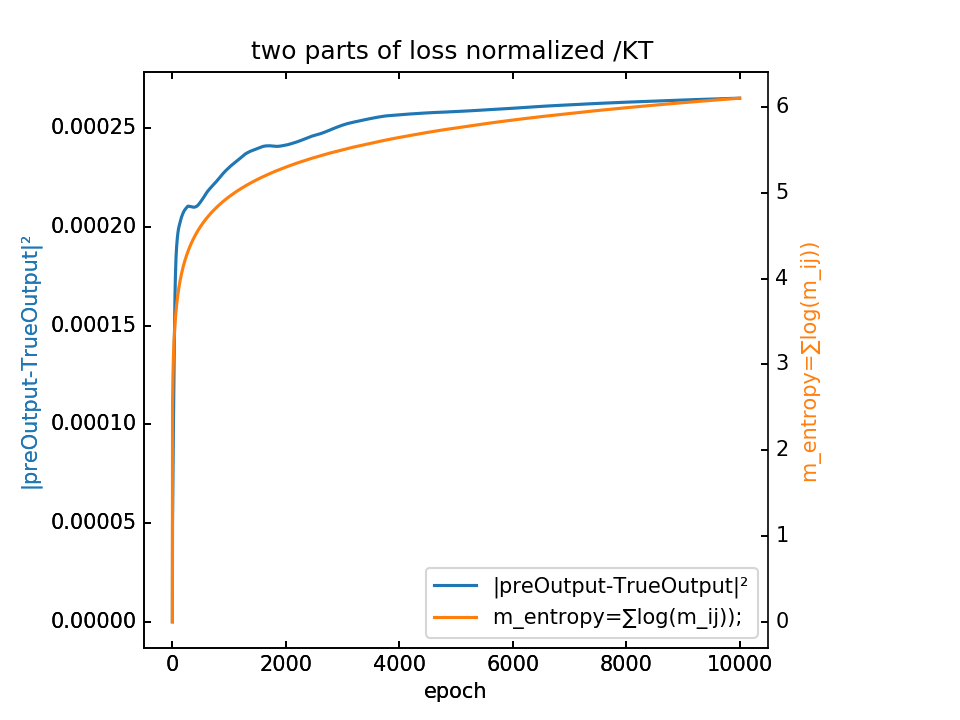
loss分为两部分,蓝-λ橙
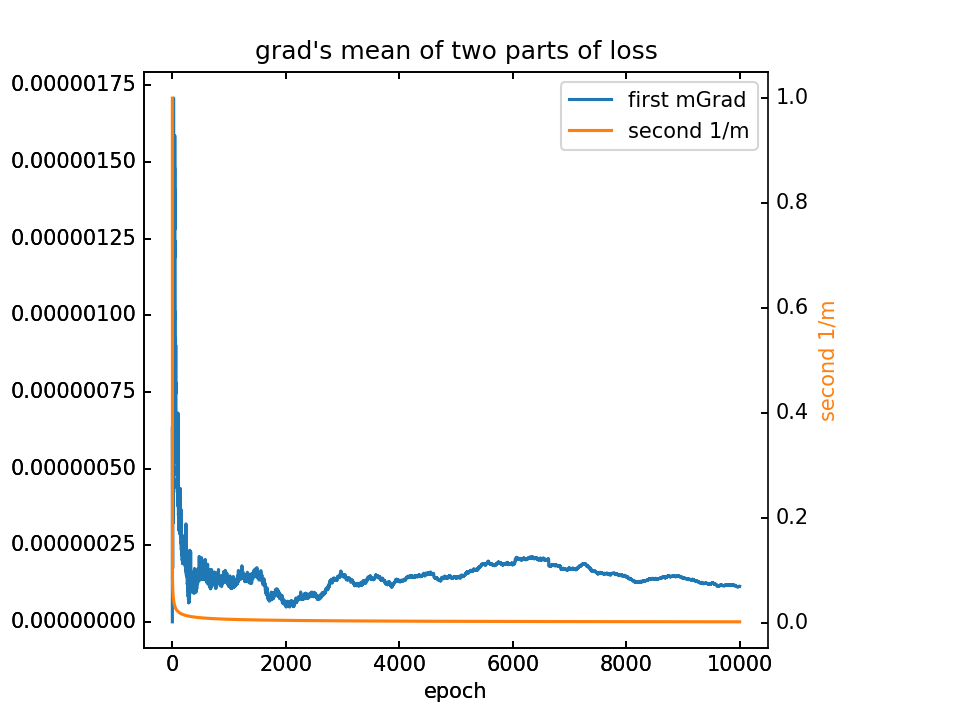

对m梯度分为两部分,蓝-λ橙。这里分别看梯度的平均值和方差
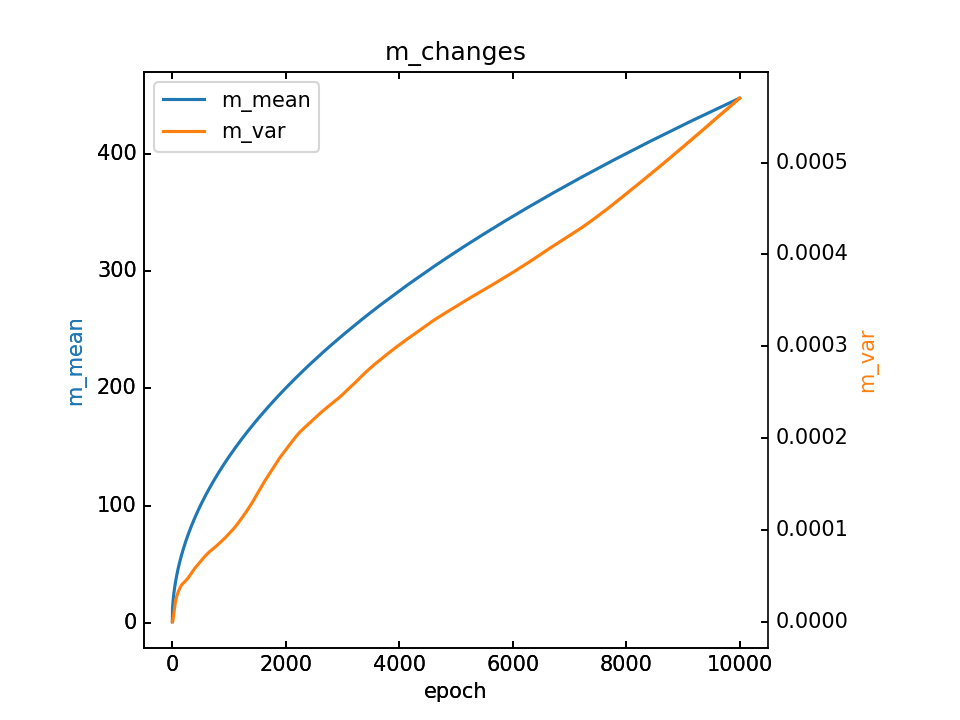
m的变化和最终m,详细
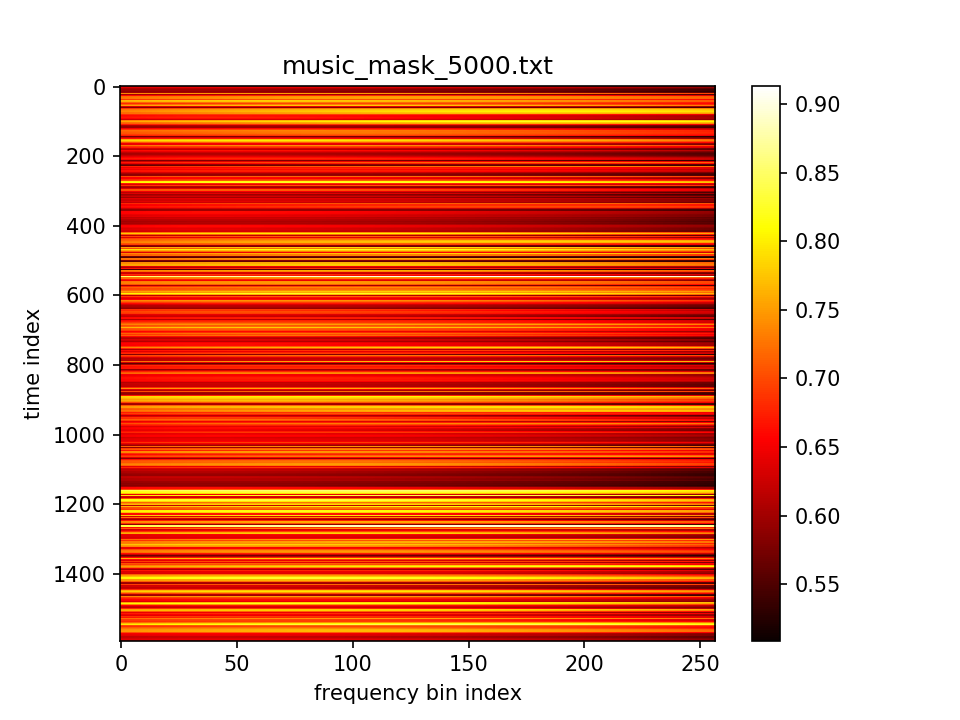
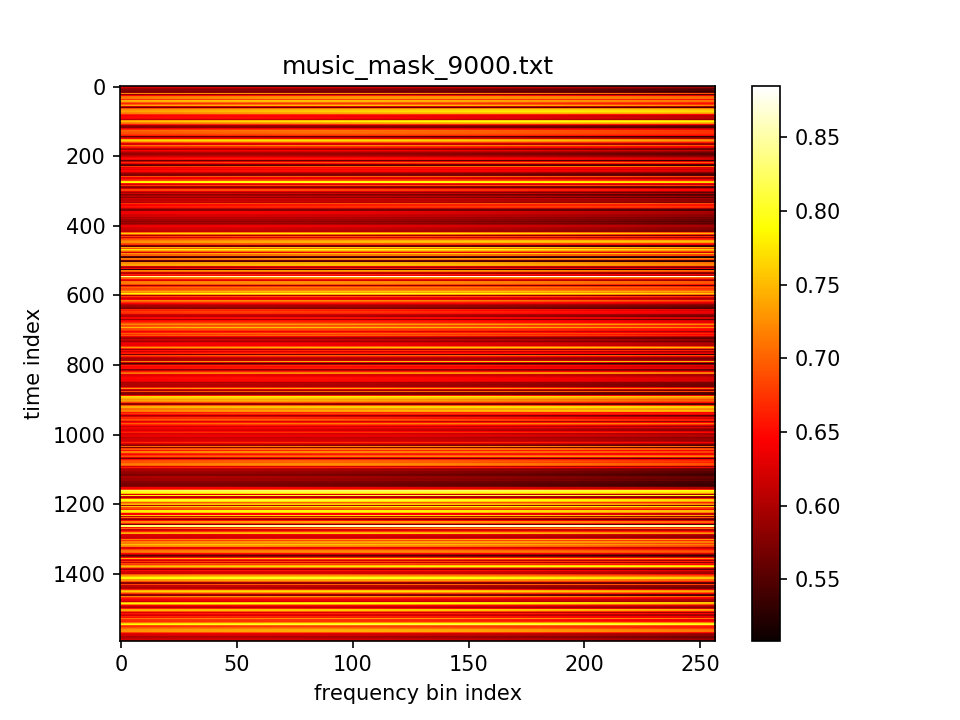
最后输出在各个维度的分布:
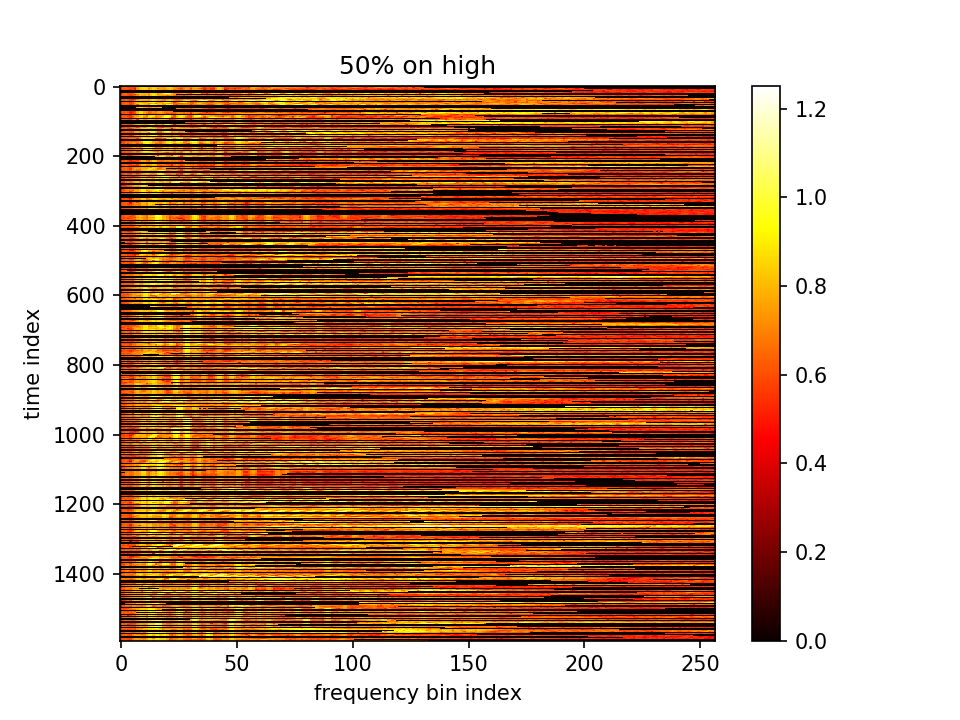
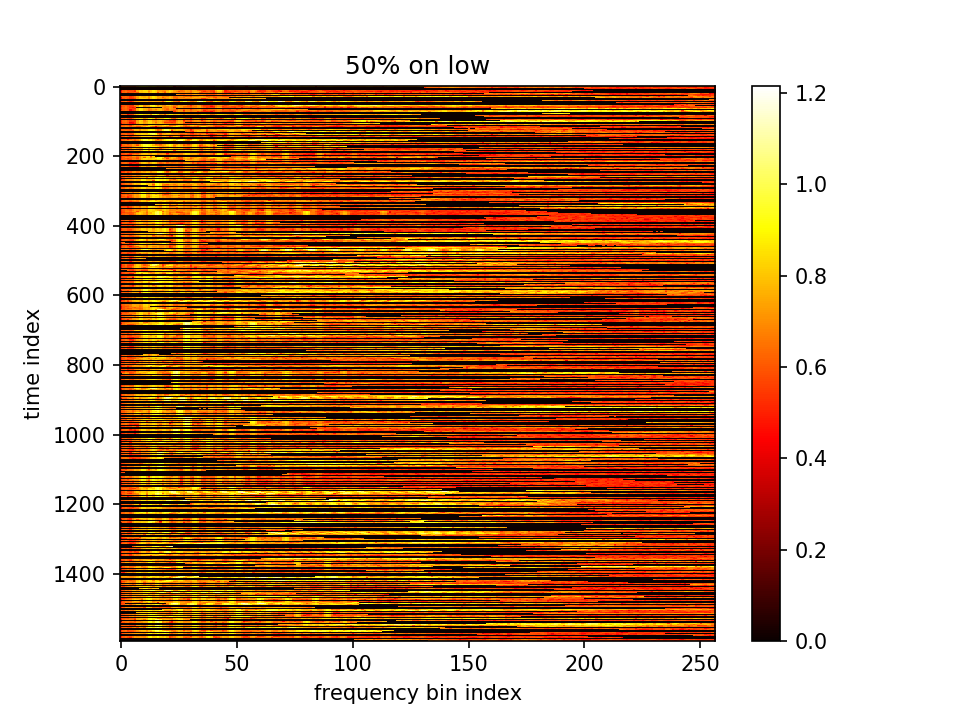
- m初值5.0,λ=1.0,10000epoch
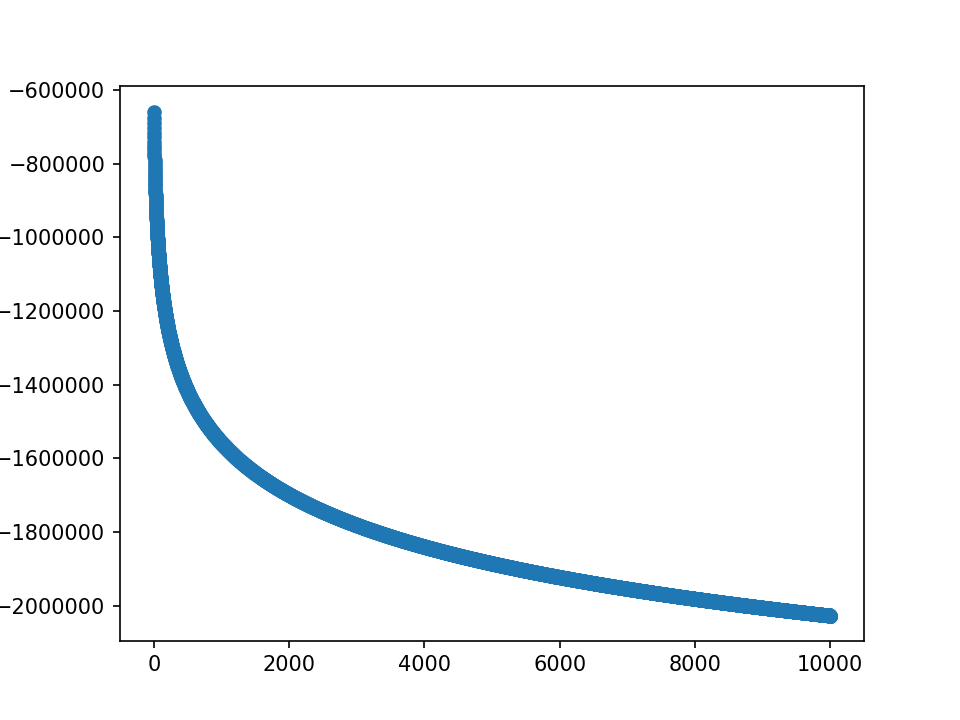
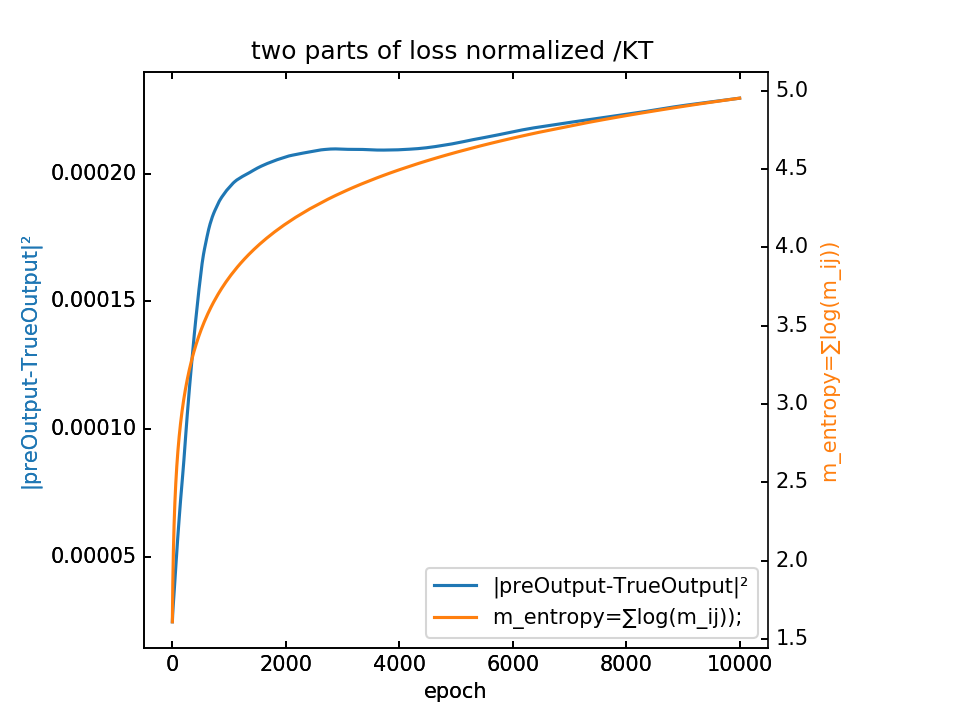
loss分为两部分,蓝-λ橙
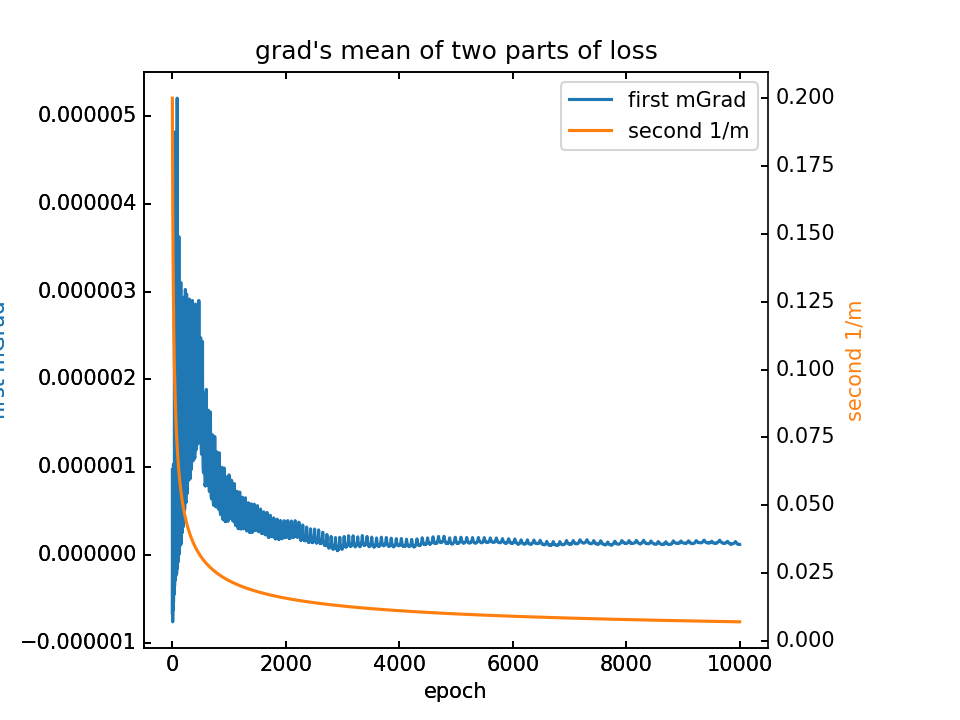
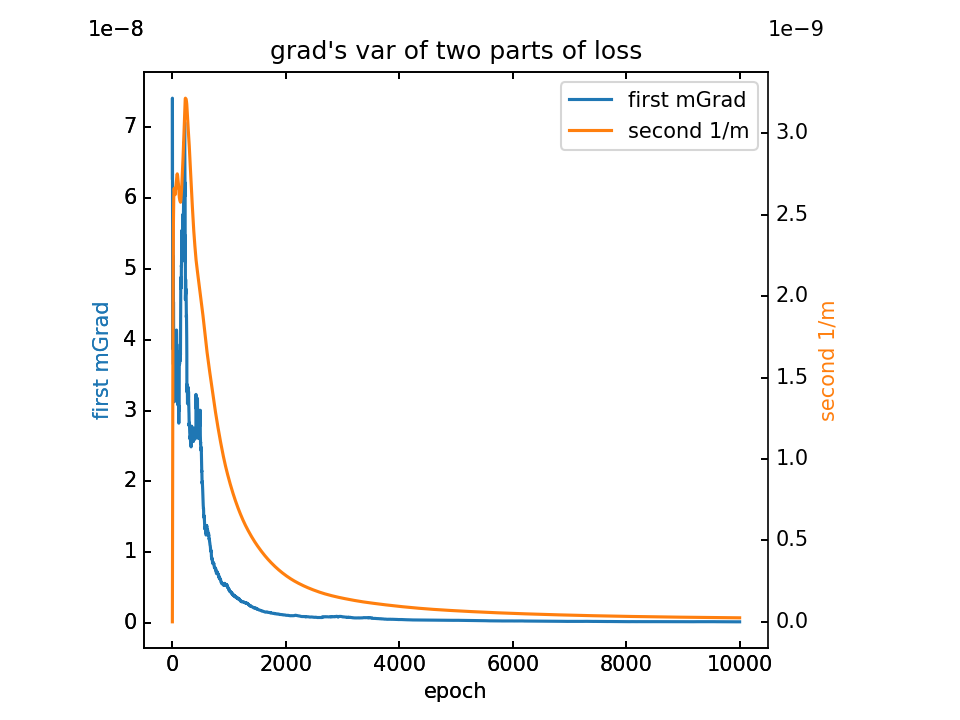
对m梯度分为两部分,蓝-λ橙。这里分别看梯度的平均值和方差
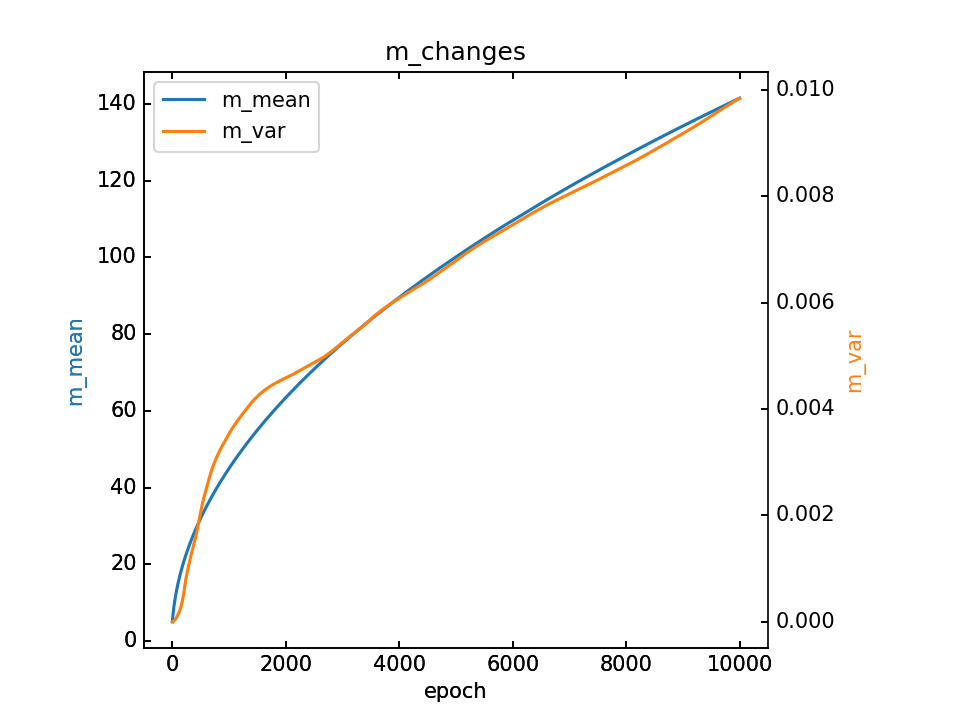

m的变化和最终m,详细
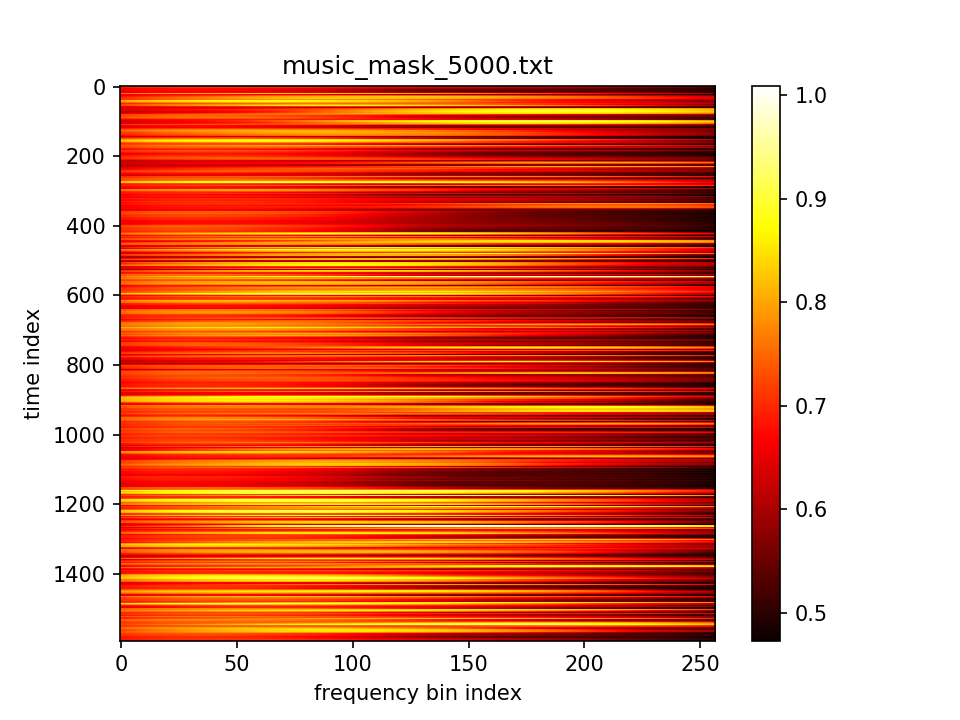
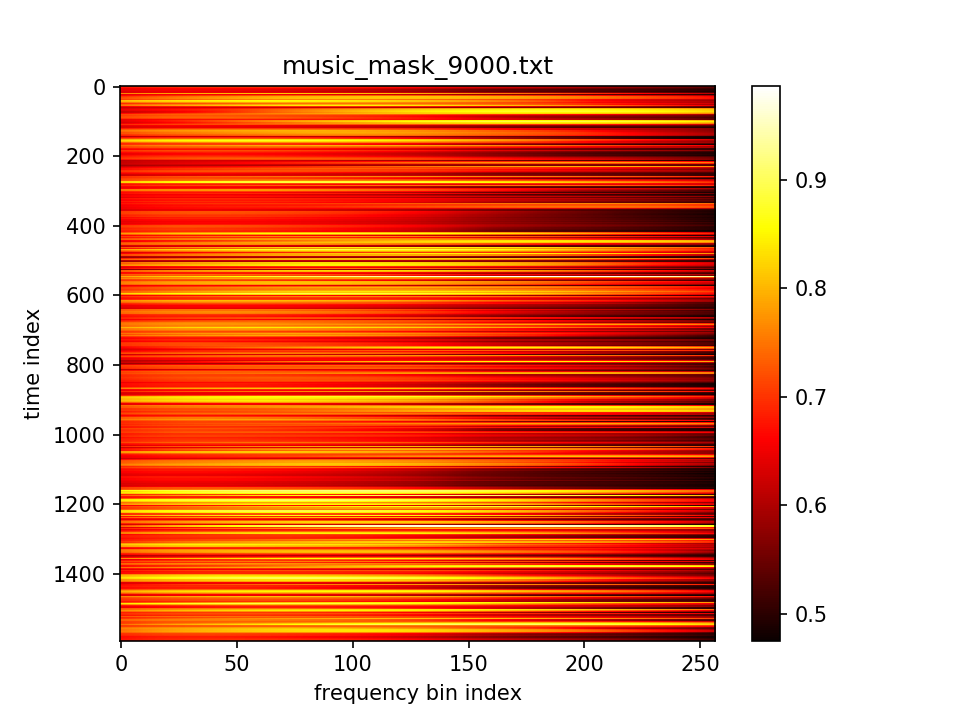
最后输出在各个维度的分布:
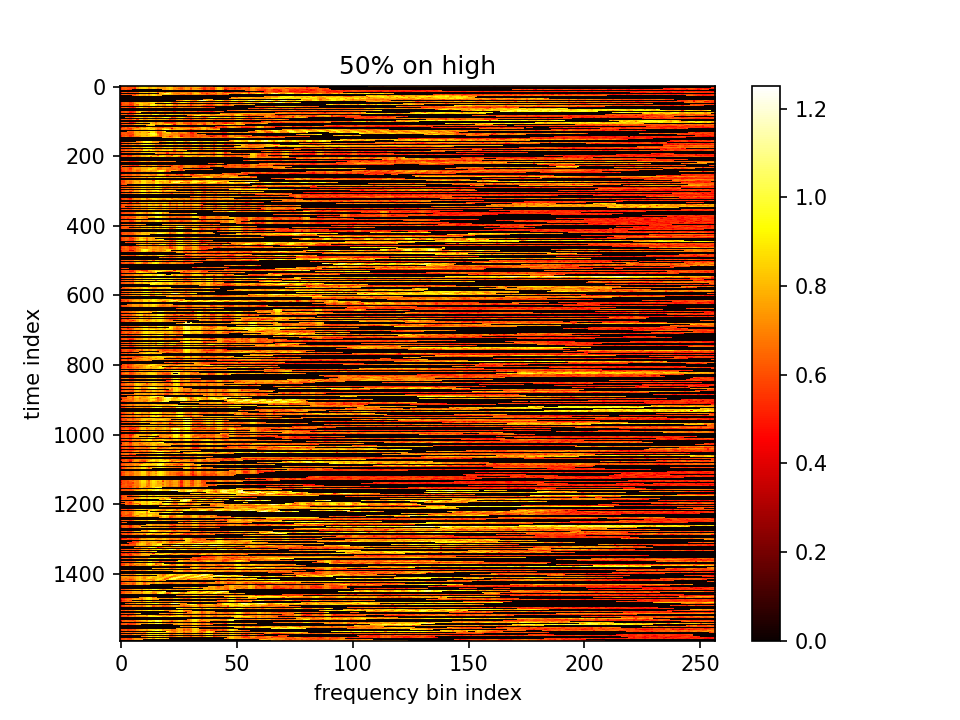
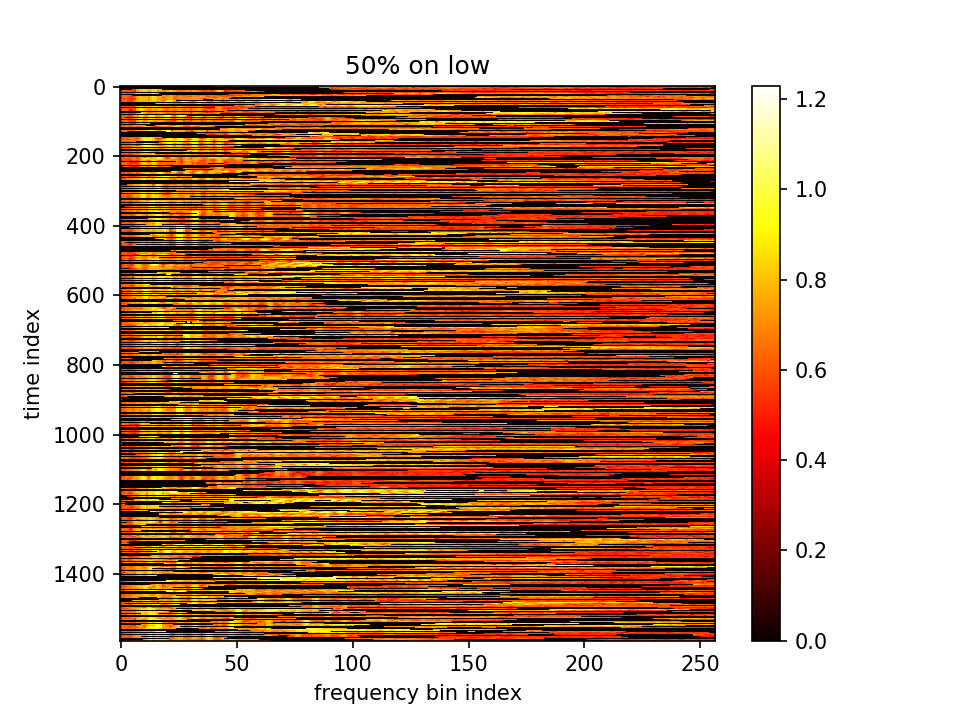
- m初值1.0,λ=0.001,10000epoch
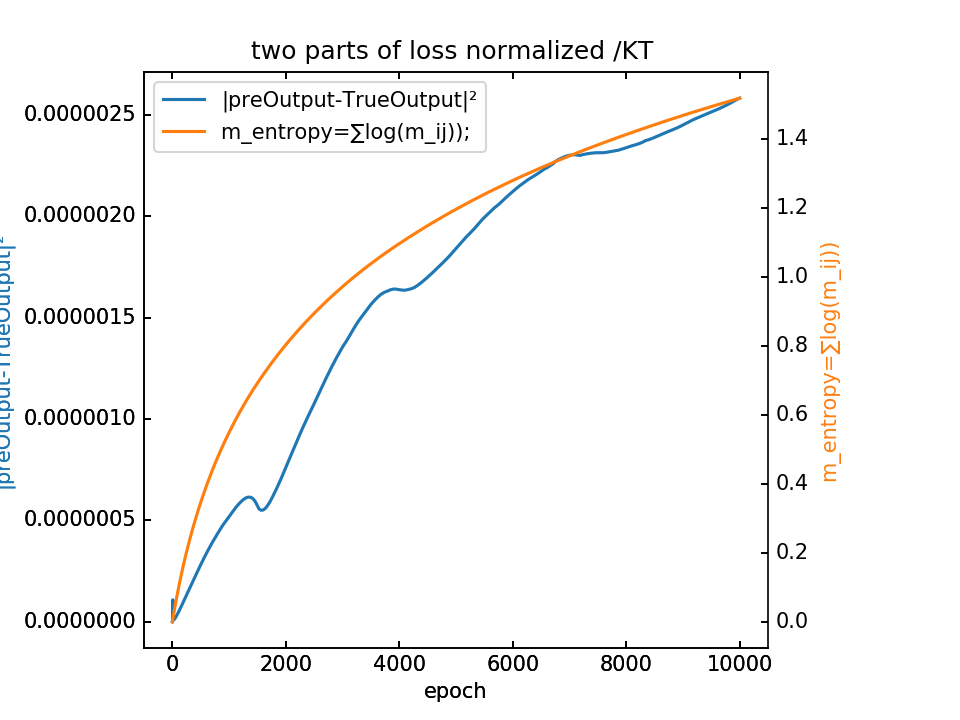
loss分为两部分,蓝-λ橙
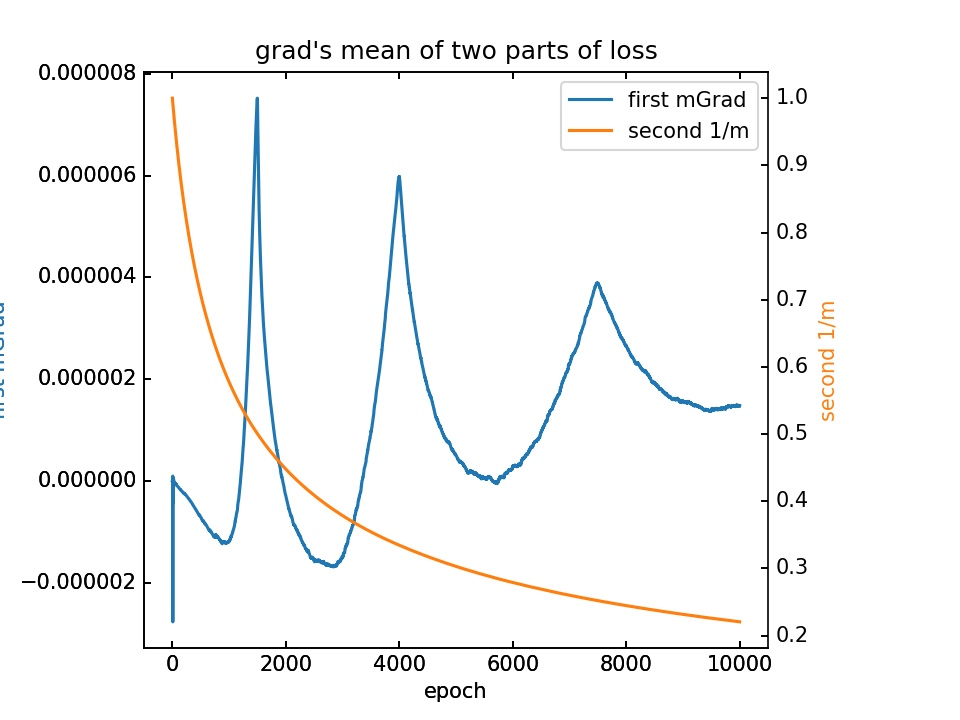
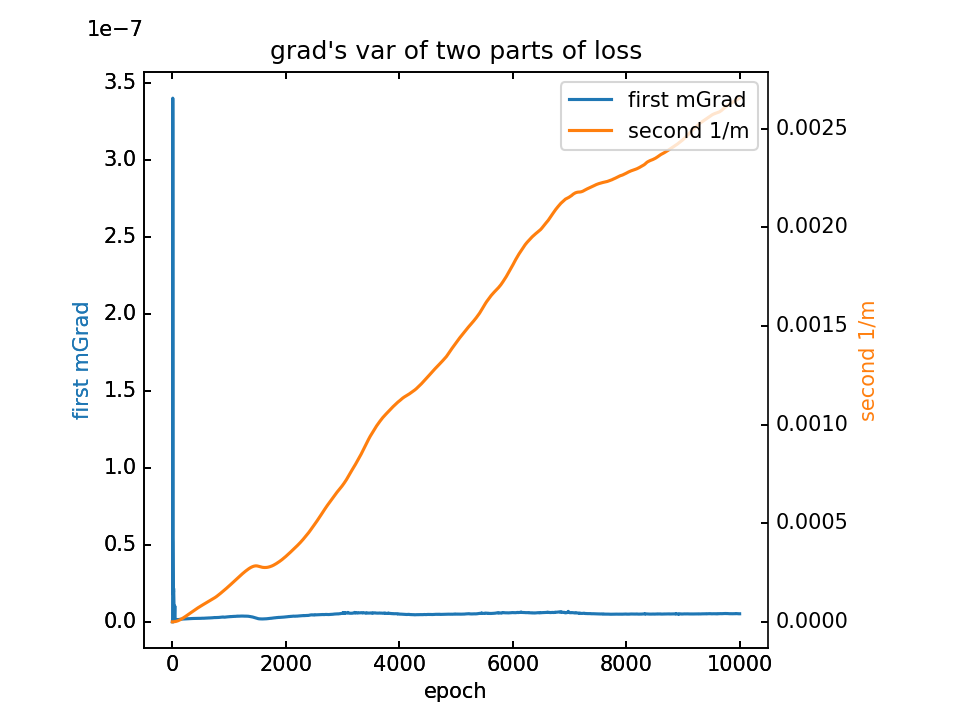
对m梯度分为两部分,蓝-λ橙。这里分别看梯度的平均值和方差
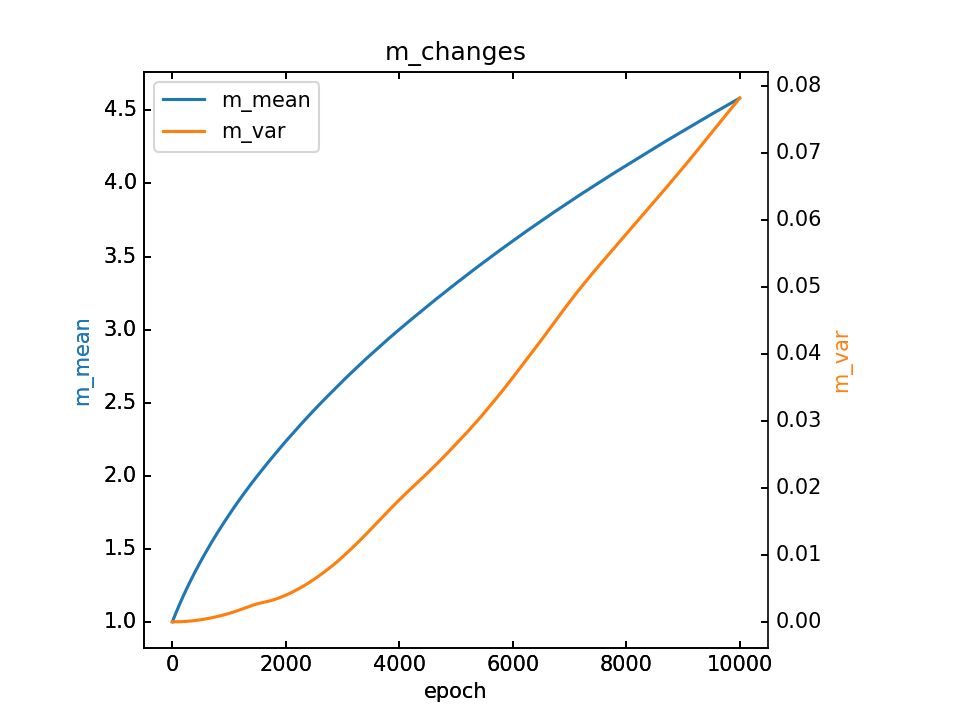
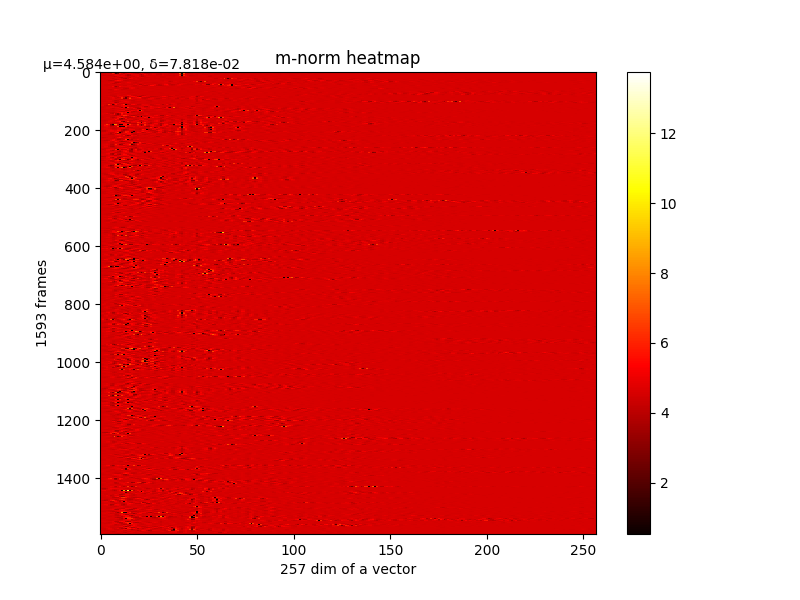
m的变化和最终m,详细
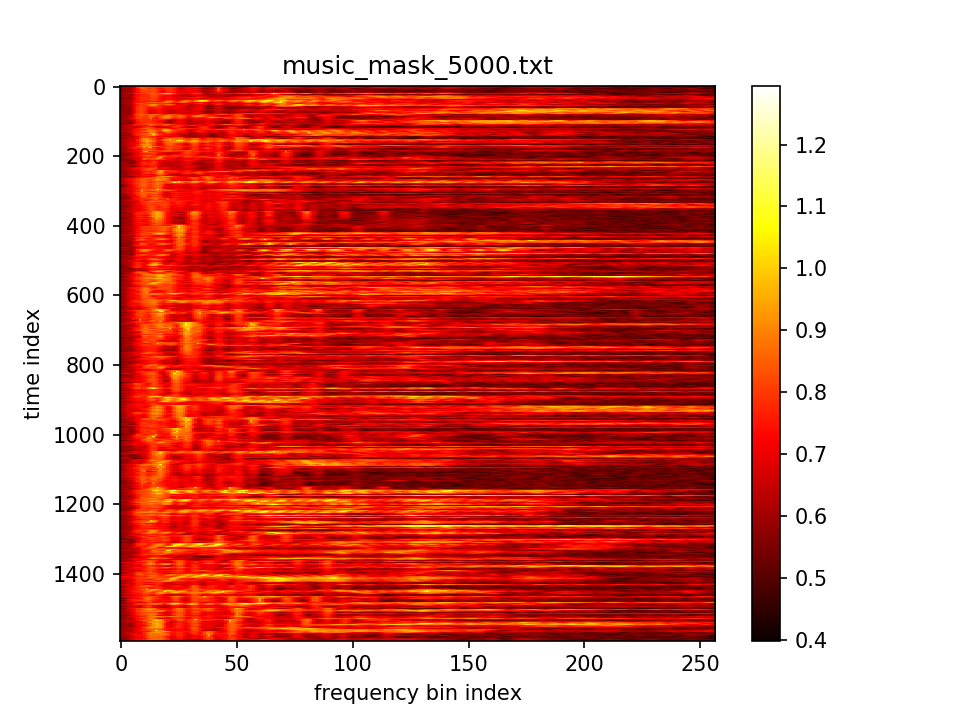
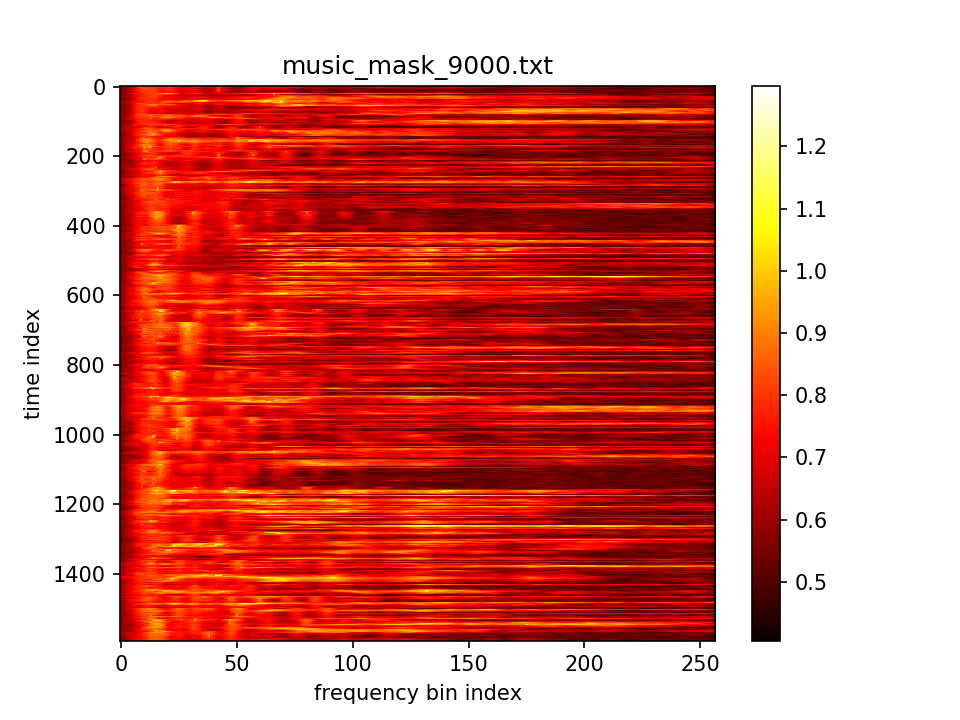
最后输出在各个维度的分布:
3.一些思考
-
1.几乎是λ越大,最终m就越大。这是符合loss公式的,因为前一项MSEloss是想让m减小,而第二项 -H(m),则是想让m变大。
-
2.看训练过程中被模糊后的音频,的确是在频率维度上做了模糊。听声音时老师指出可以听声母和韵母的保留度有所不同,可以在后续对原语音点进行标记并比较。
-
3.最终m的值都差不多,这是我们不希望看到的结果。但是通过看置零m后的图,置零的部分在频率维度上往往是连着的,这个地方值得研究。而关于如何让m的区分度更大,我目前想到了两个方向:
-
4.第一,之前对于边界点的考虑是直接将外面舍弃,比如有一个在最边上
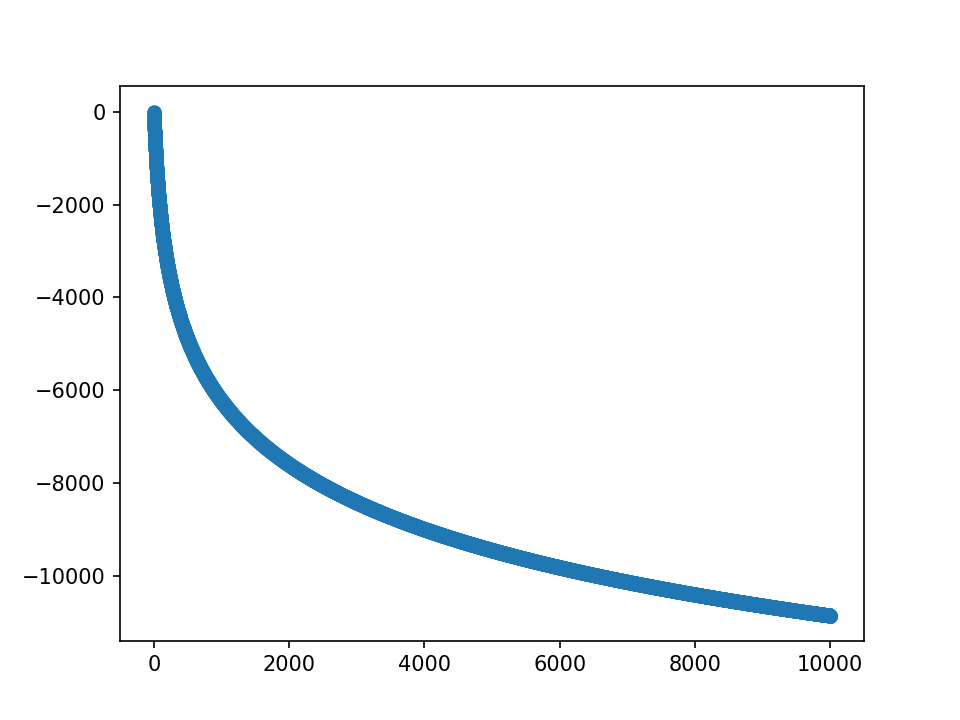
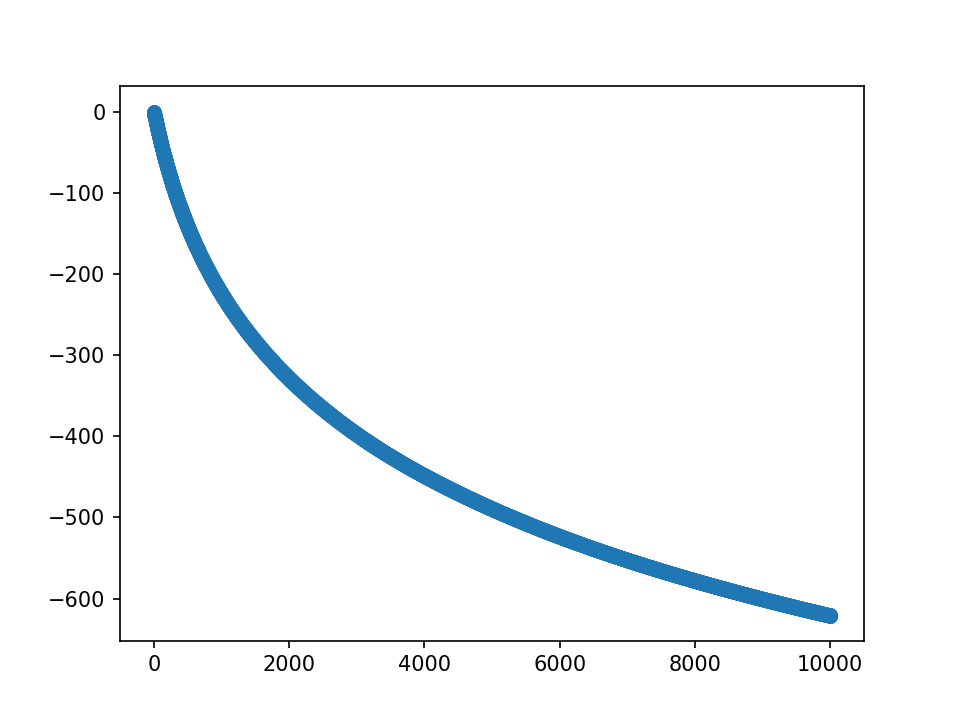
m=3, fft=9的点,就直接保留内部的1 2 3而舍弃外部的2 1,这样每次fft矩阵的总值会减少一点;但是显然,m越大,这样丢弃的值就越多,比如看这一组fft矩阵的均值变化:
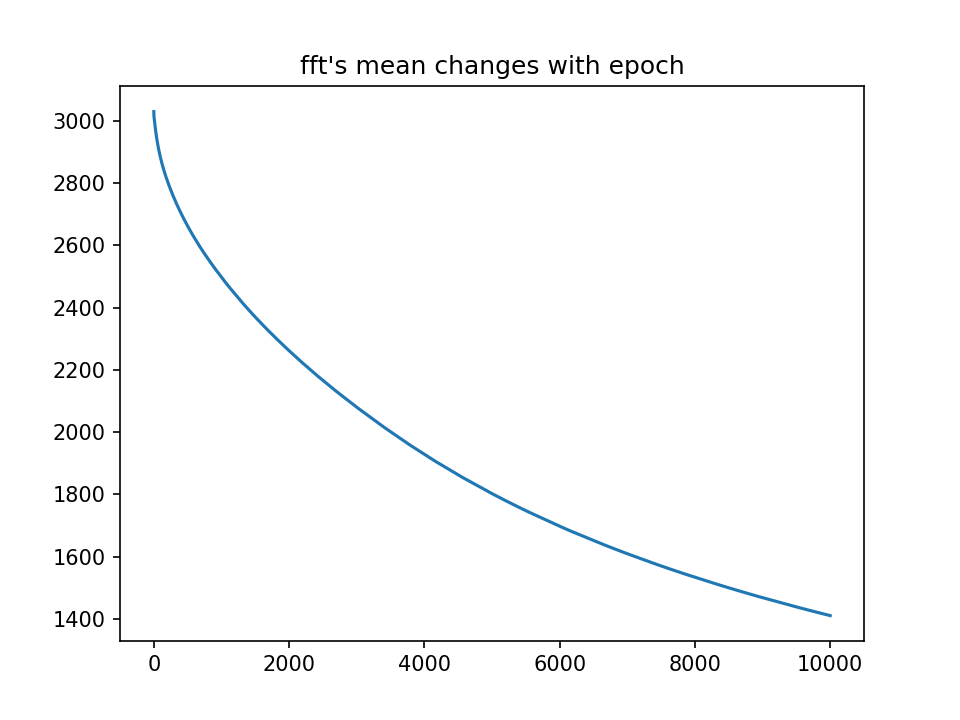
λ=10, 最终m均值为400
可以看到,每次丢一点,fft的值被丢了很多。因此选择先求周边影响点的变化,然后本身值的变化就是减去其他的加值,这样可以确保fft矩阵的值总不变。如下:
af::array f1_1 = absTiled*(MTiled-af::abs(iloop-ploop))/sum_m_p_j; //i!=p, add
af::array f1_2 = absTiled*(sum_m_p_j - sum_mpj_partial_to_mpj*(MTiled-abs(iloop-ploop)))/(sum_m_p_j*sum_m_p_j); //i!=p, grad
Z_add = cond * ((1 - i_e_p) * f1_1);
Z_grad = cond * ((1 - i_e_p) * f1_2);
af::array f2_1 = (-1.0)*af::tile(af::sum(Z_add, 2), af::dim4(1, 1, K)); //i==p, add
af::array f2_2 = (-1.0)*af::tile(af::sum(Z_grad, 2), af::dim4(1, 1, K)); //i==p, grad
Z_add += cond * i_e_p * f2_1;
Z_grad += cond * i_e_p * f2_2;
- 5.分析loss和grad的量级。
loss的尺度:MSEloss在e1左右,而H(m)loss在e6左右。其中第二项好理解,归一化(除以KT)之后就是log(m),比如m=5,归一化后loss即log(5)=1.6。
而梯度的尺度:分析梯度的平均值,MSEloss的梯度在e-5,后一项梯度就是1/m,在e-1。
m=m-lr*grad,目前设的lr=1.0,则梯度直接导致m变化的量级。以前λ都乘在后一项上,而前一项的e-5总是很小,不能对e0量级的m造成足够变化。而前一项是对不同m坐标点敏感的,现在其太小,则最后m都差不多大。
所以将λ乘在前一项上,先设λ=e5。
4.保持fft总值不变
- m初值5.0,λ=1.0,10000epoch,保持fft不变
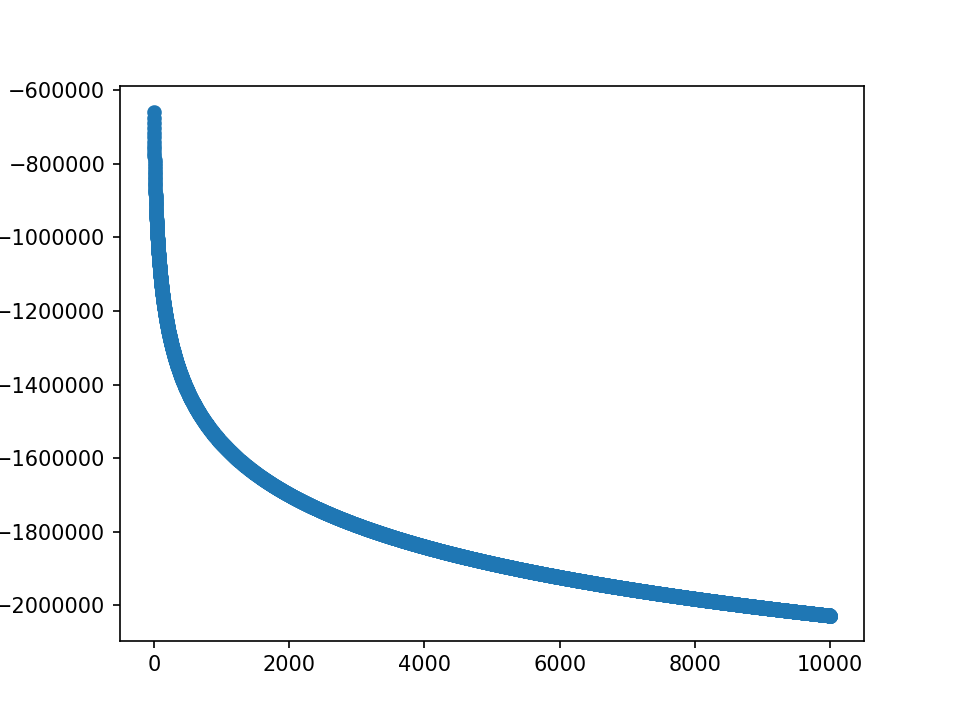
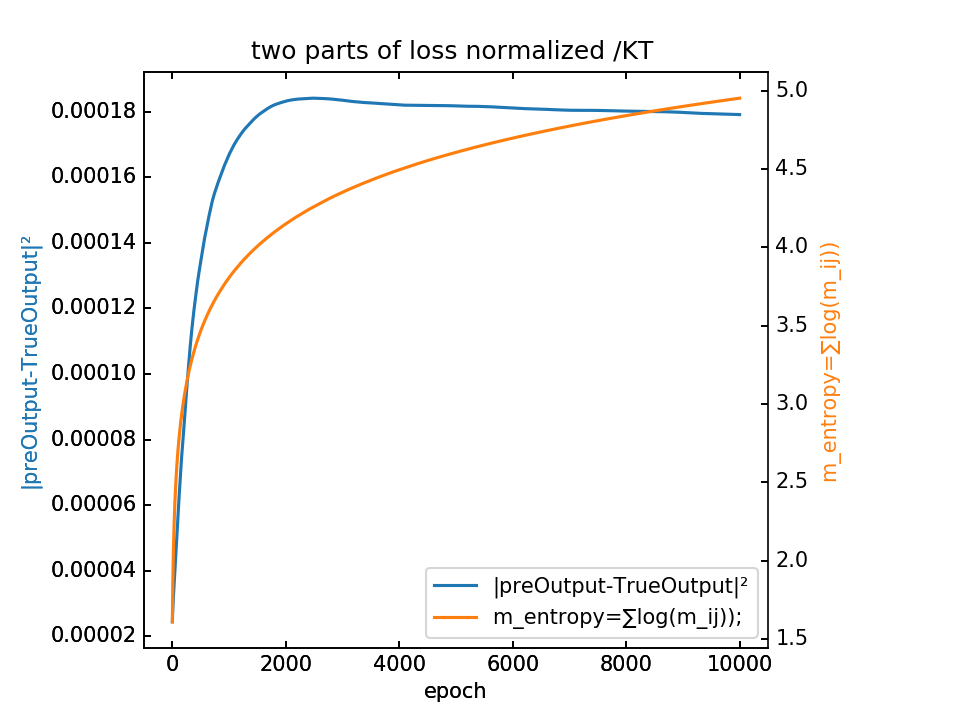
loss分为两部分,蓝-λ橙
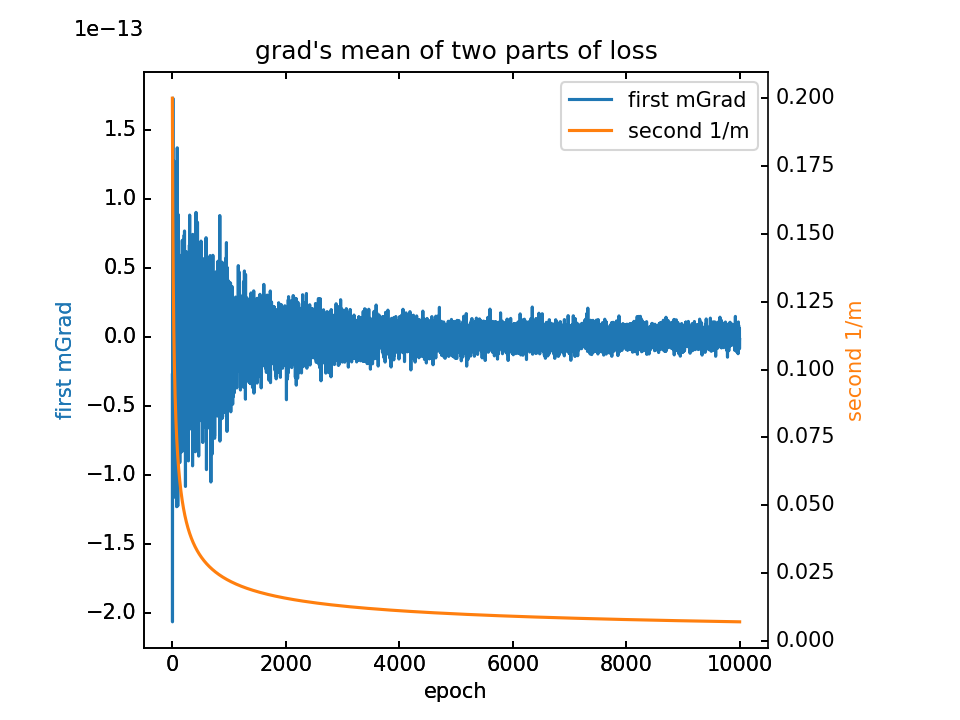
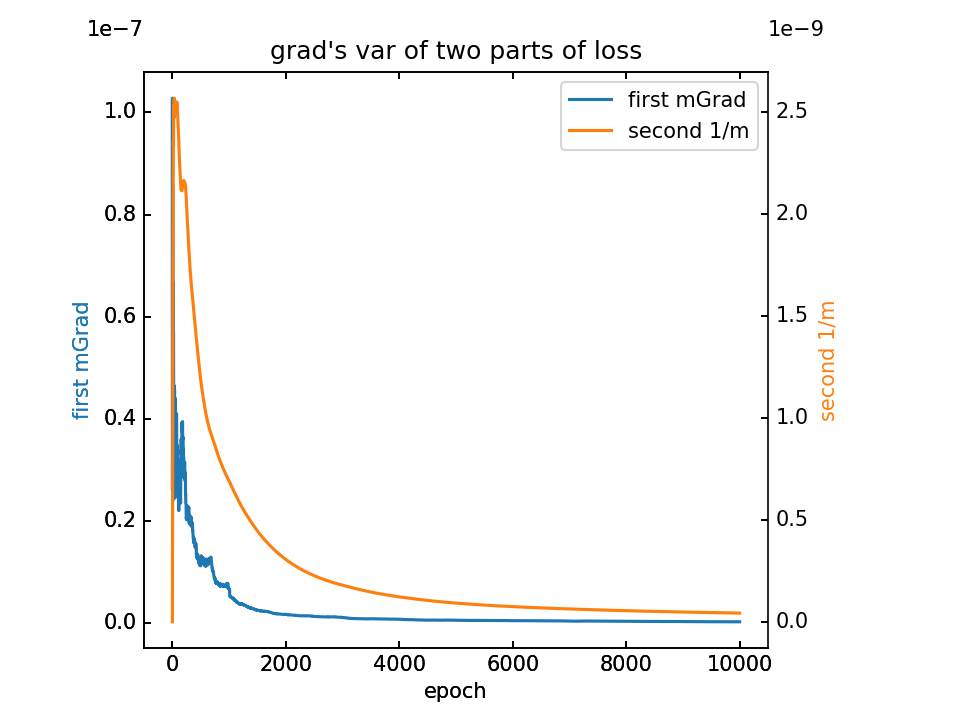
对m梯度分为两部分,蓝-λ橙。这里分别看梯度的平均值和方差
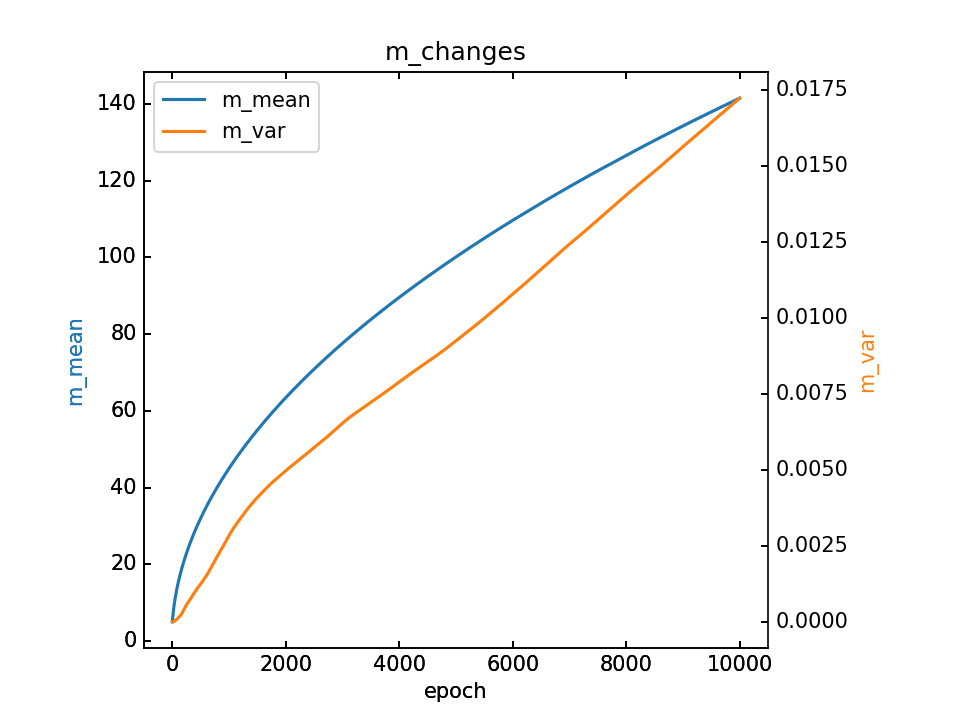
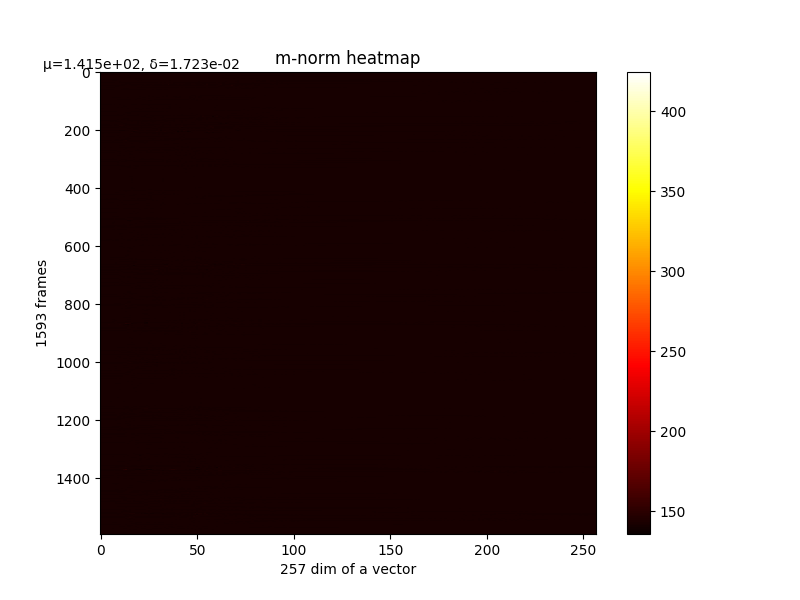
m的变化和最终m,详细
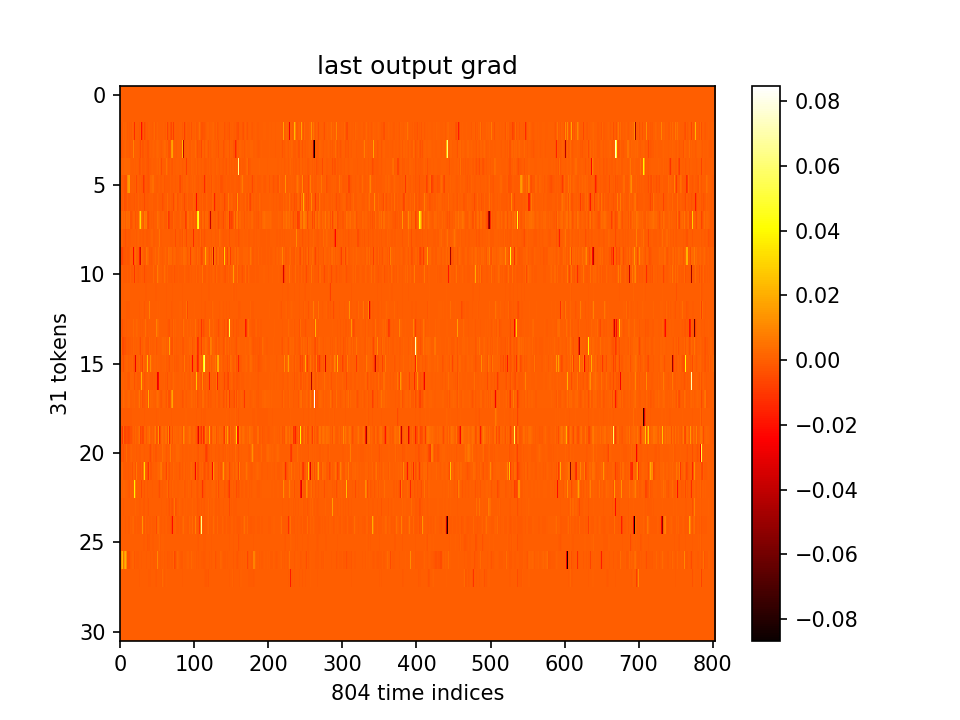
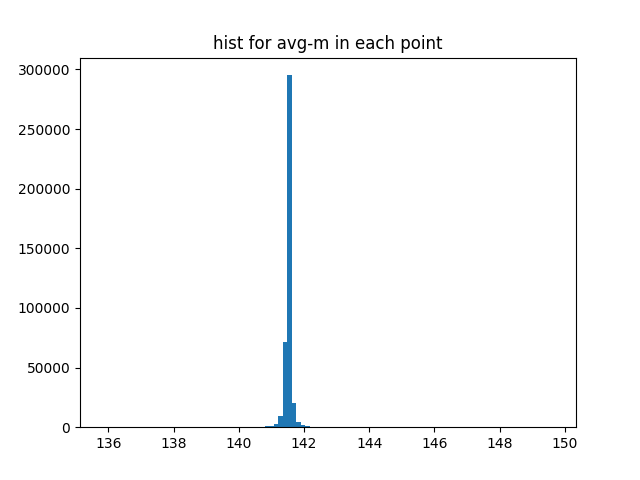
最后一层的梯度和m分布直方图
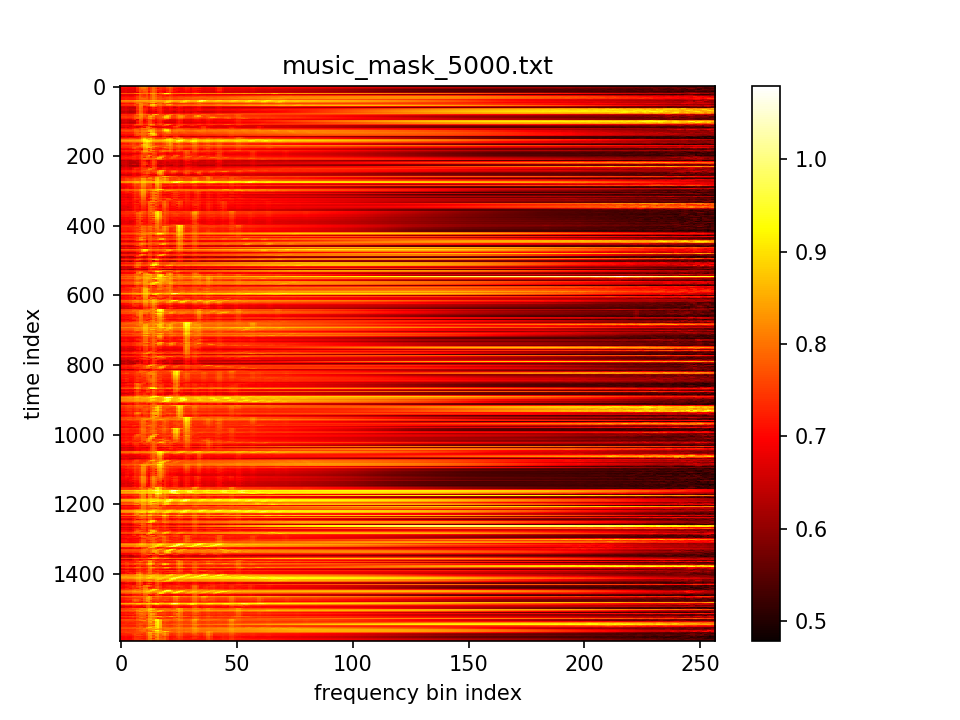
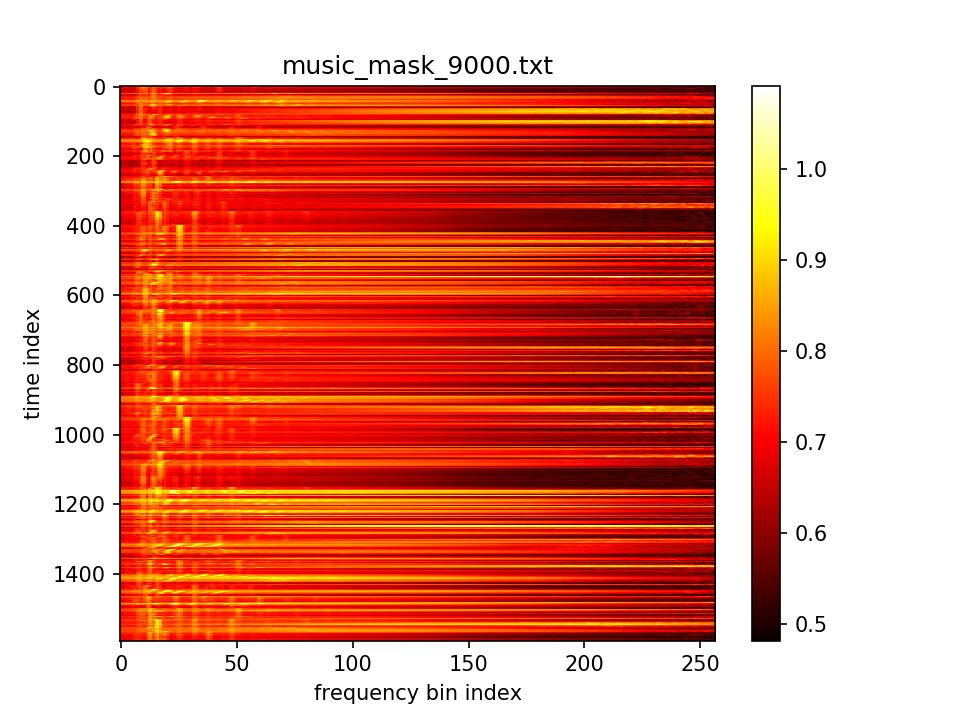
最后输出在各个维度的分布:
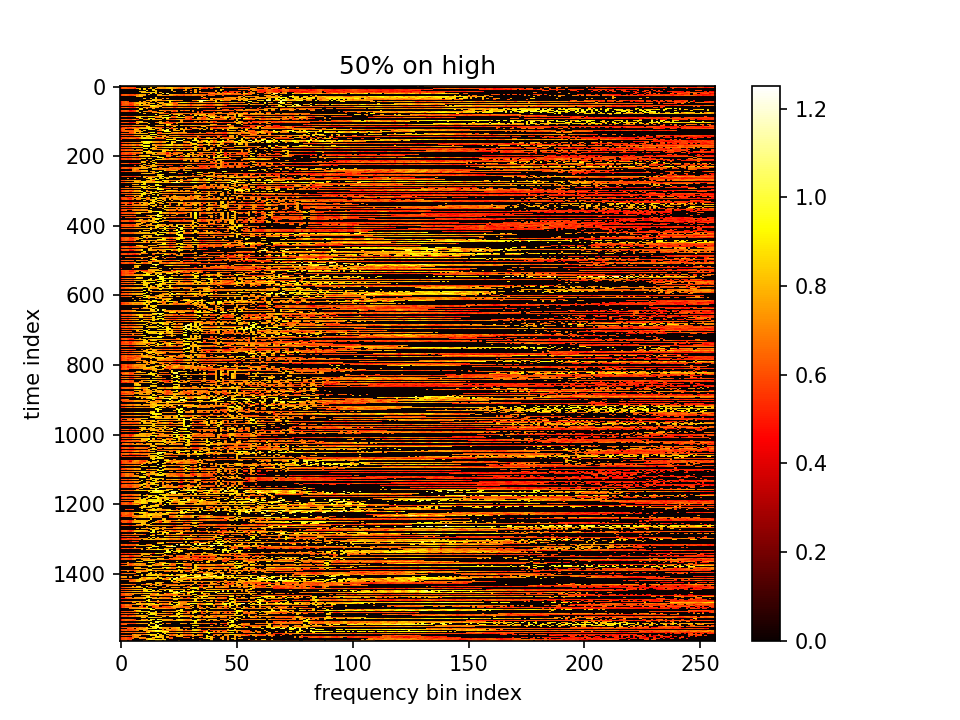
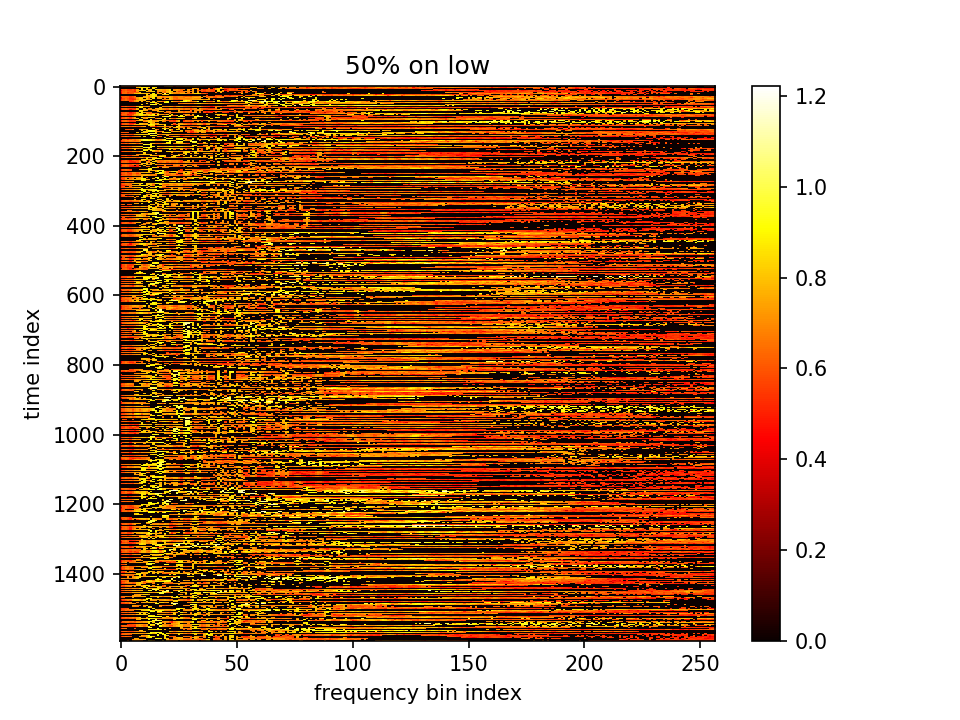
5.设置λ乘在前一项上
- m初值5.0,λ=100000,10000epoch,保持fft不变,且乘在前一项上
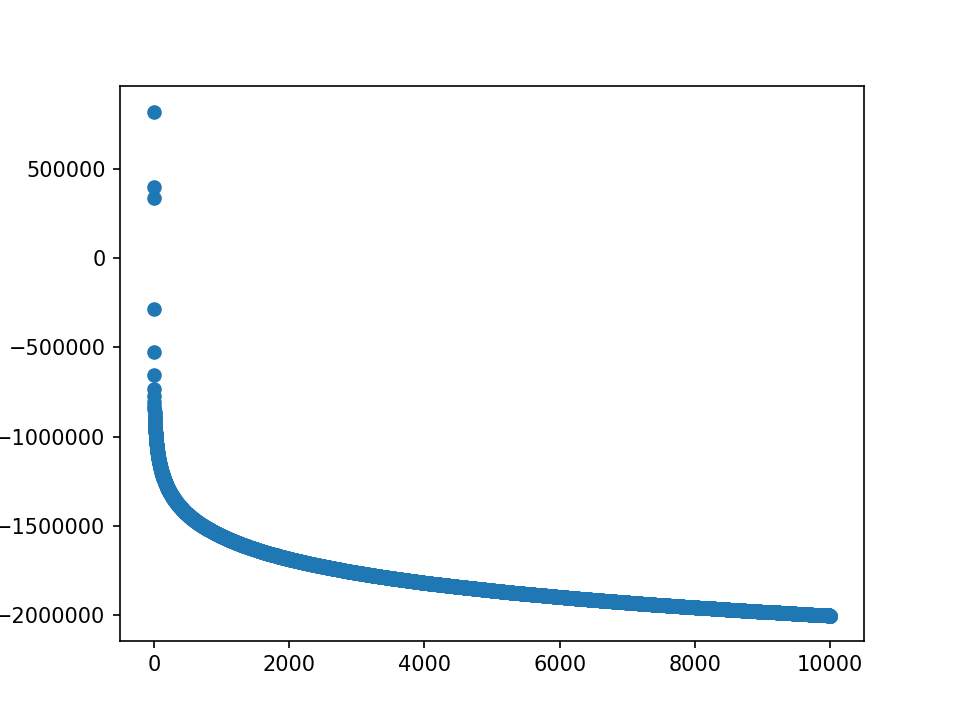
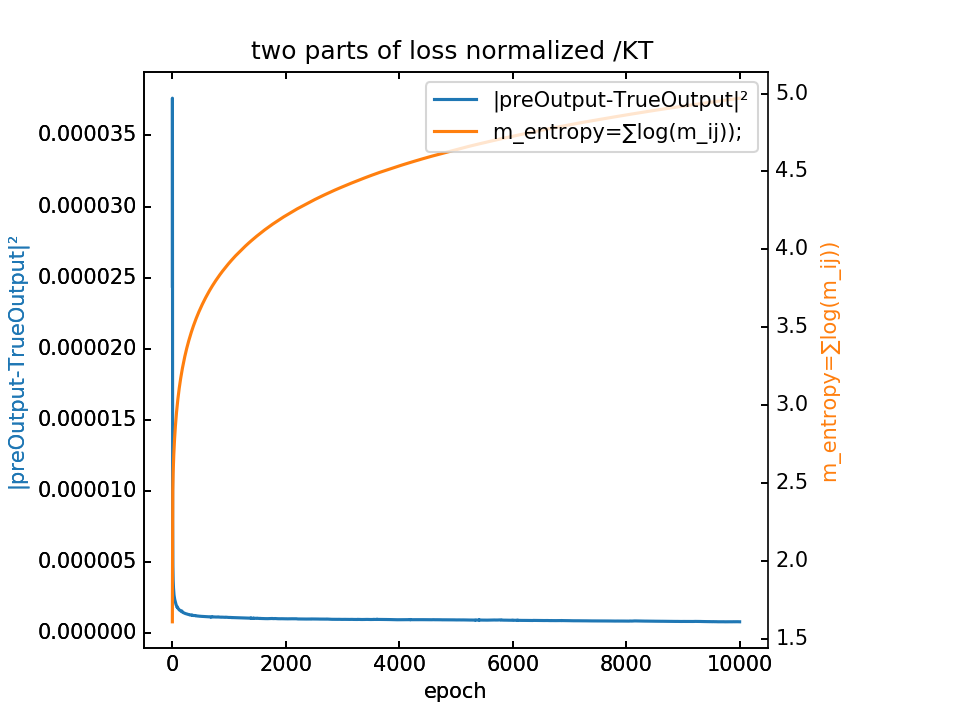
loss分为两部分,蓝-λ橙
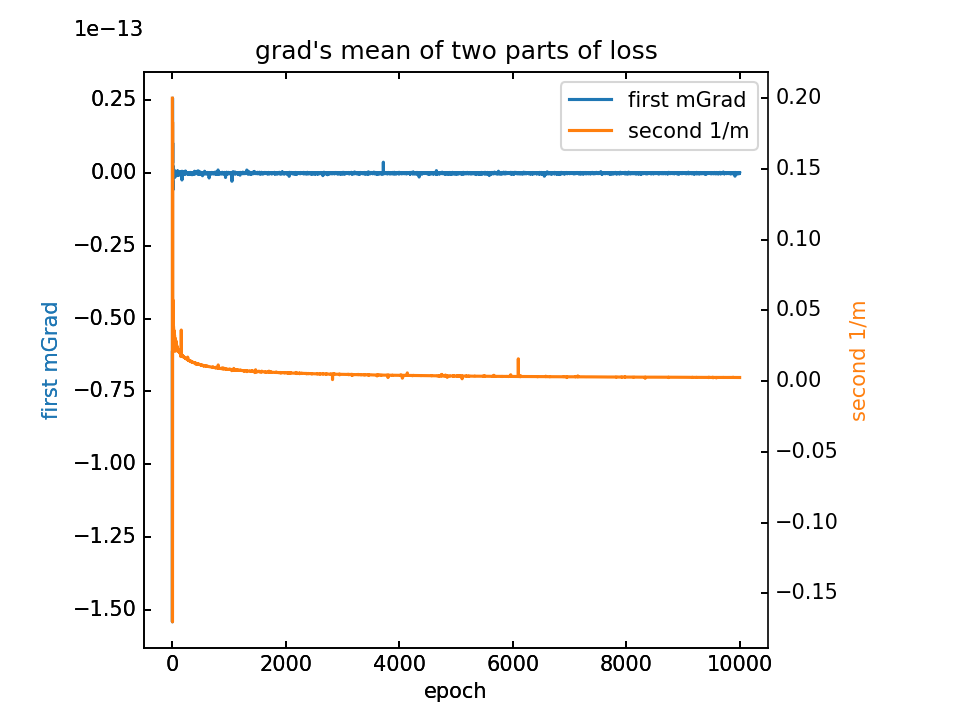
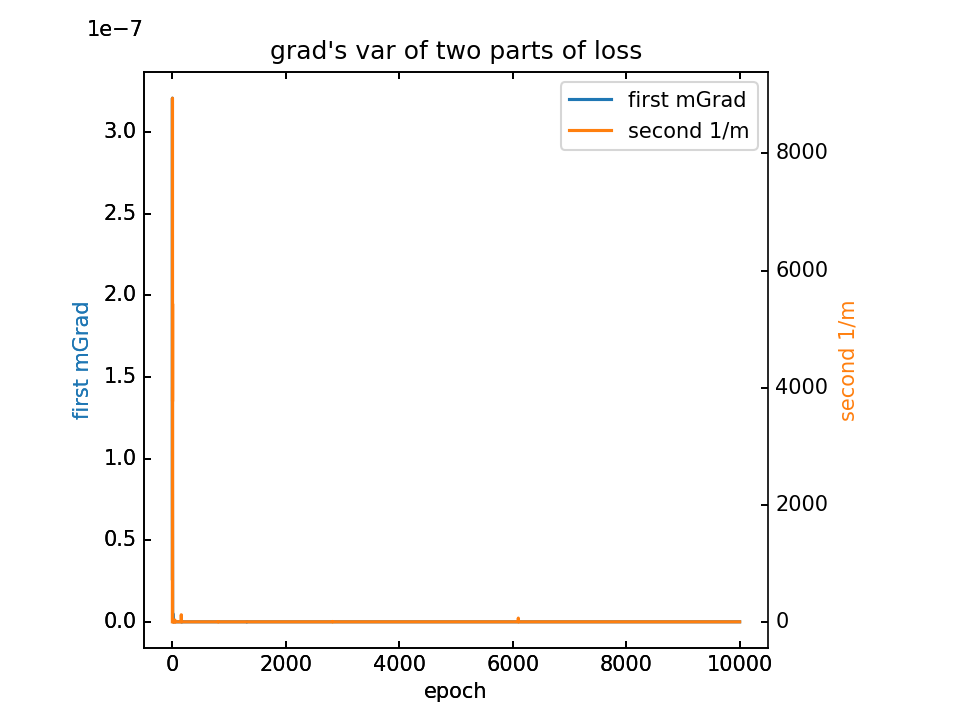
对m梯度分为两部分,蓝-λ橙。这里分别看梯度的平均值和方差
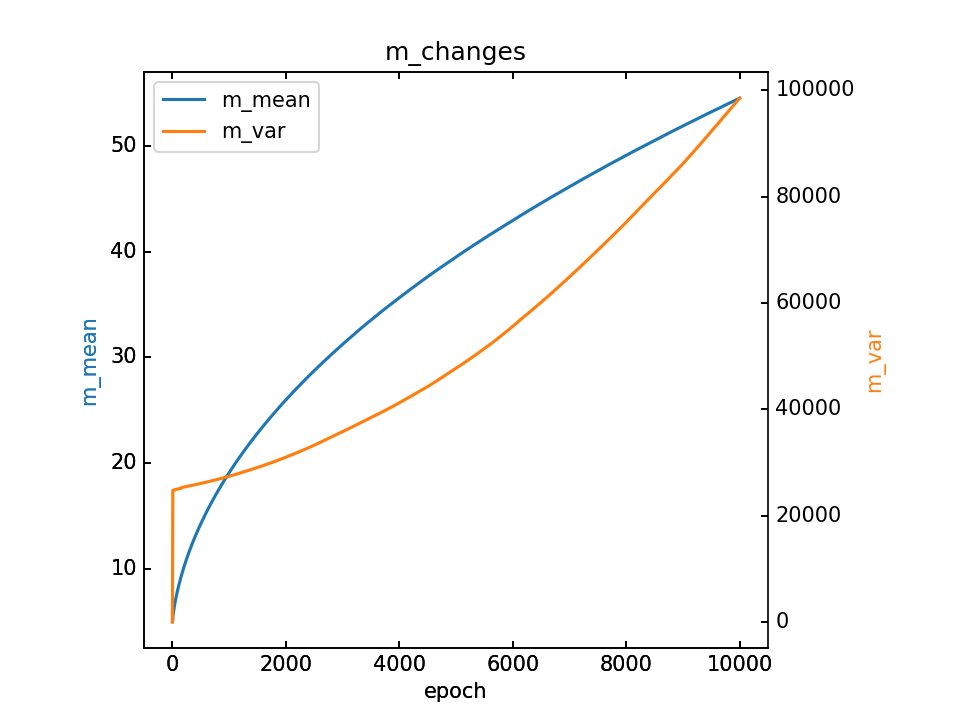
m的变化和最终m,详细
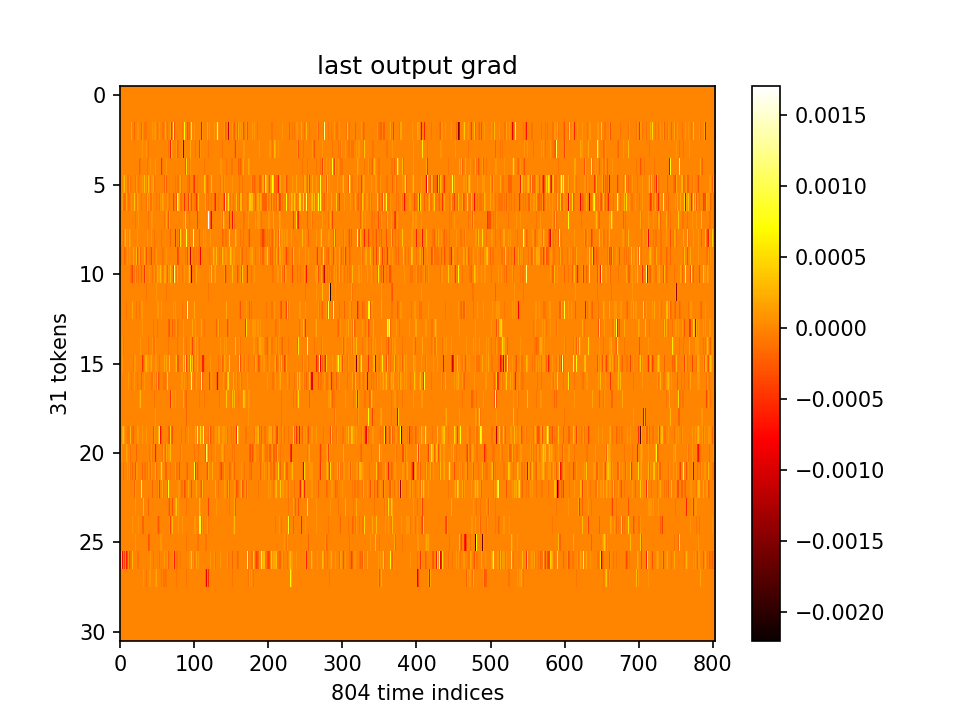
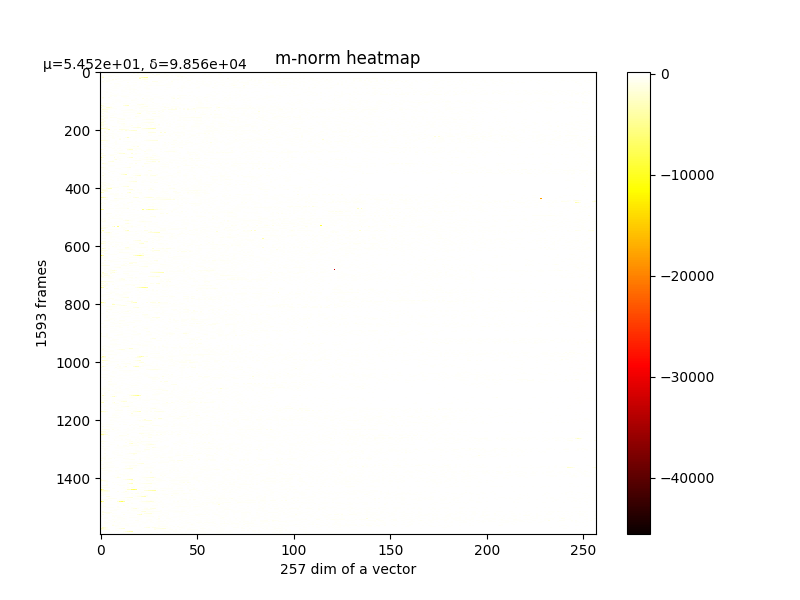
最后一层的梯度和m分布直方图
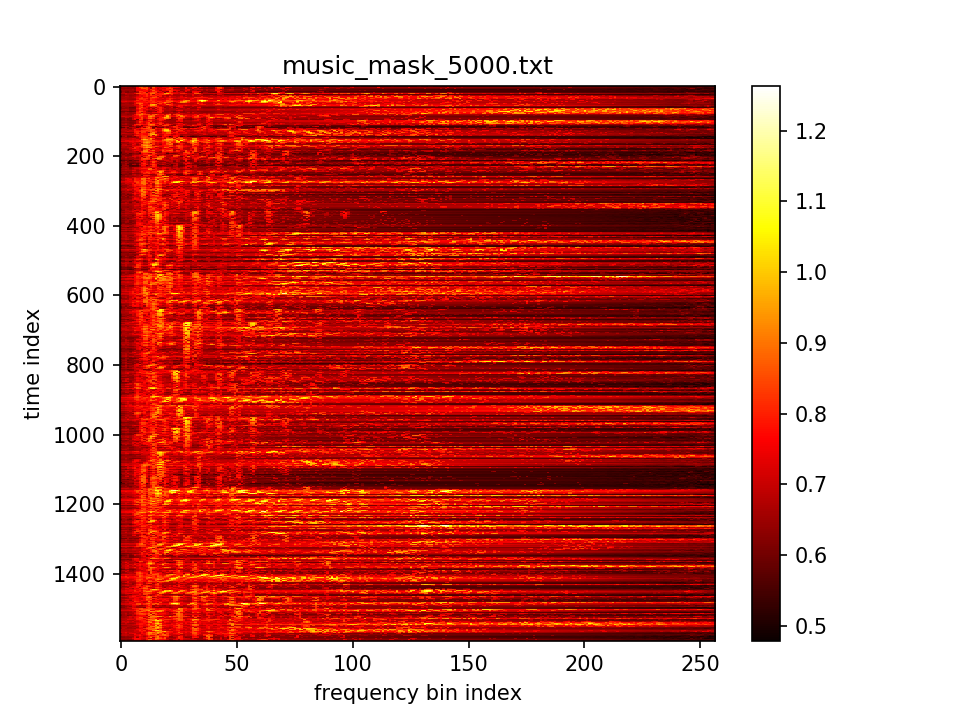
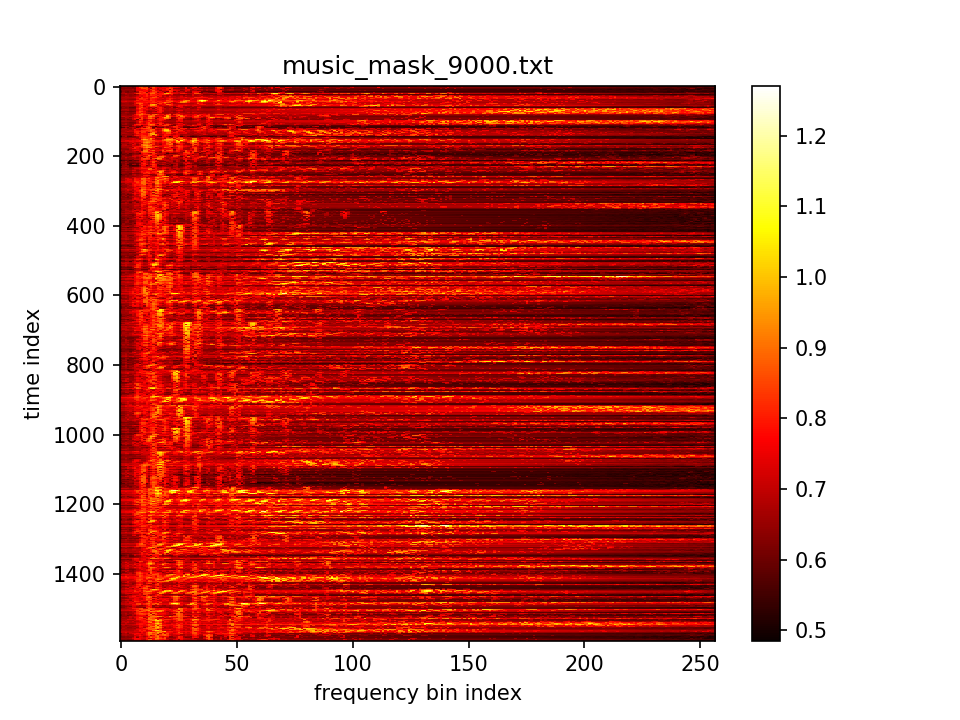
最后输出在各个维度的分布:
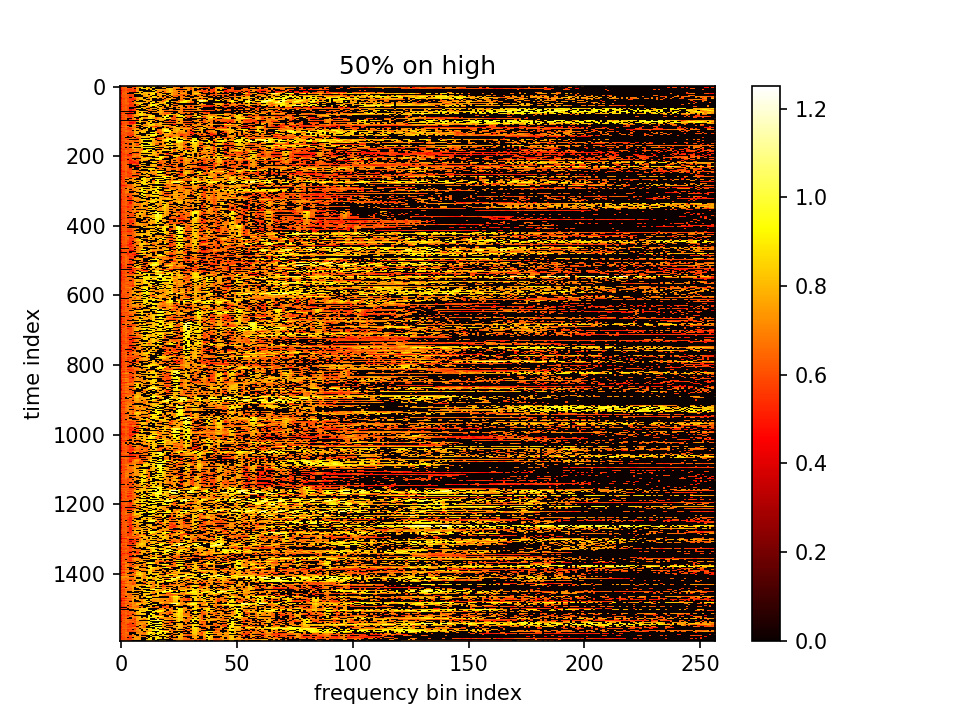
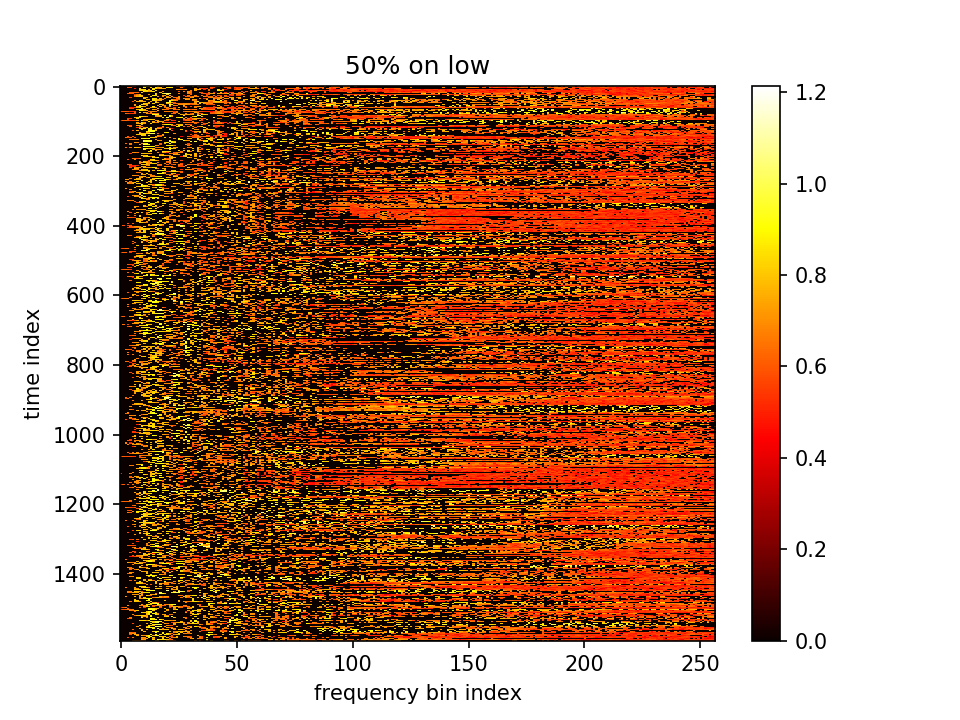
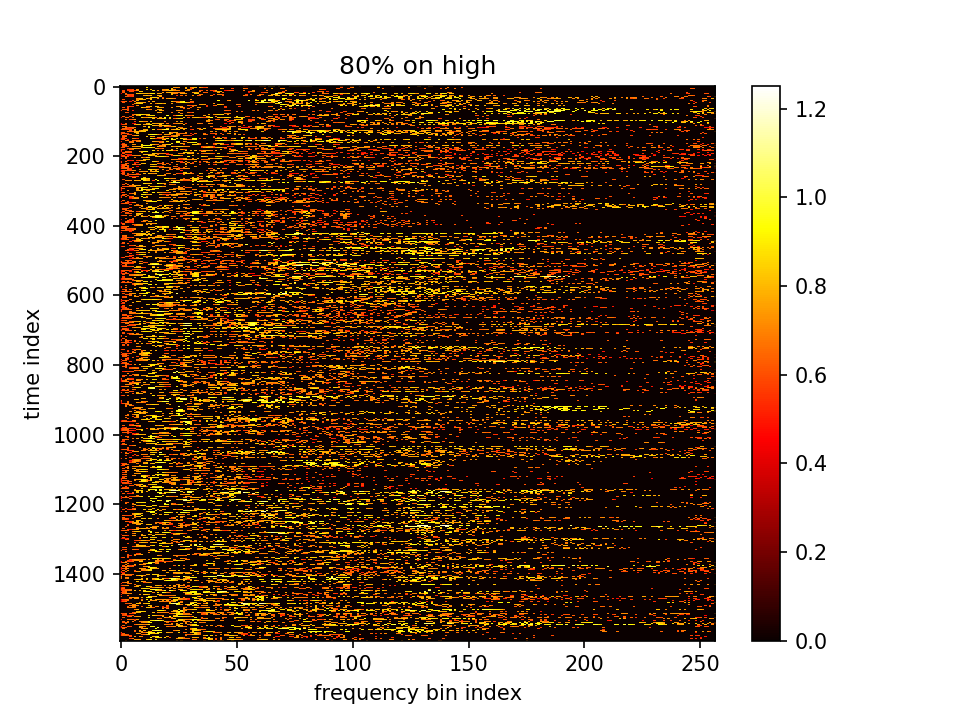
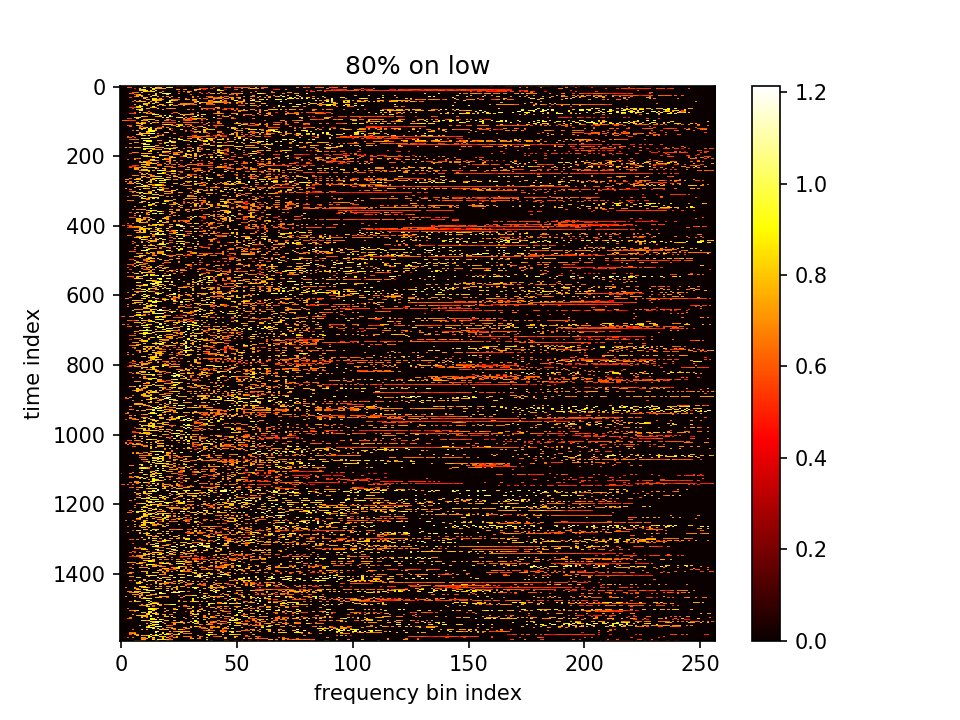
这一组可以看出m的分化变大了,不同点的m有较大区分。但是又会造成一个影响,因为MSEloss是想让m减小,m这组有很多剪到了负值。虽然算log时用了abs,但是算法就没有道理了。
因此考虑加一层relu,每次迭代初,将m为负的部分都置零。
- m初值5.0,λ=10000,10000epoch,保持fft不变,且乘在前一项上,加relu不考虑m负的点
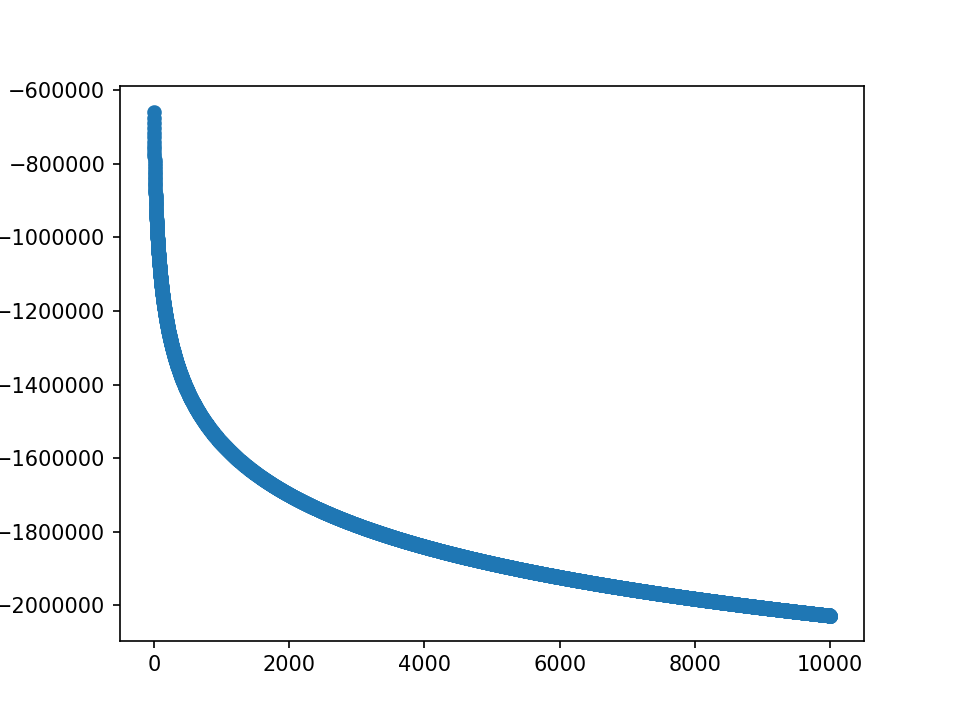
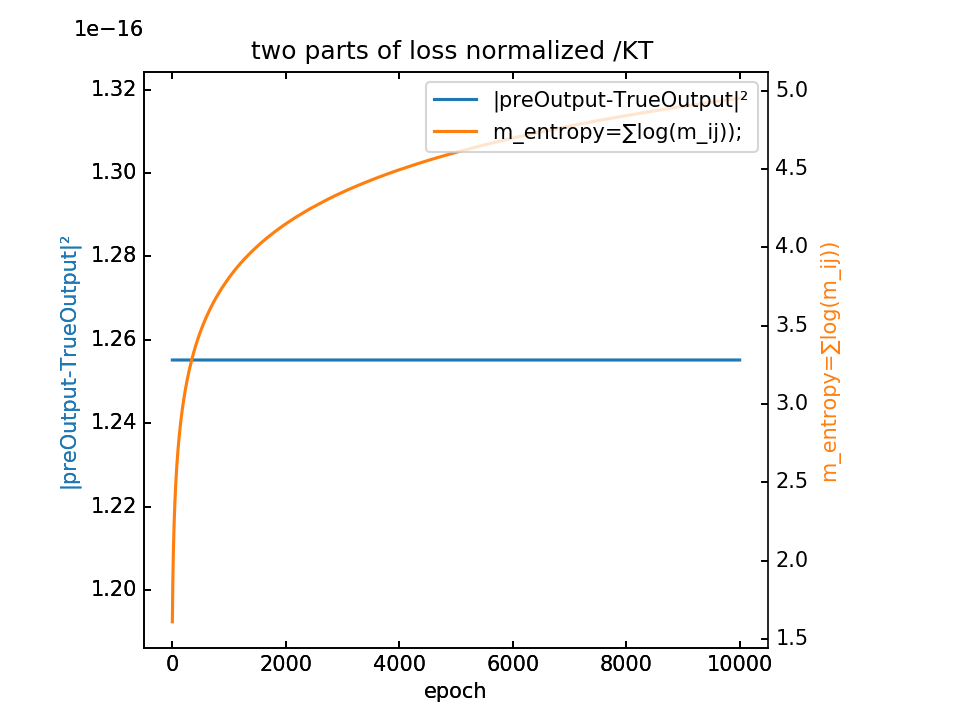
loss分为两部分,蓝-λ橙
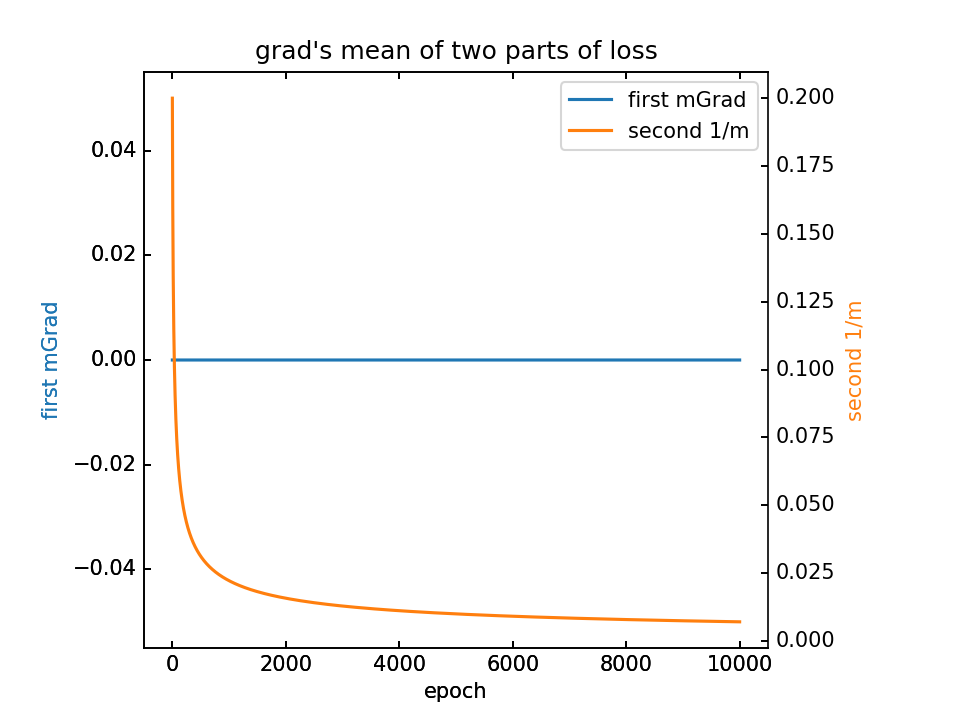
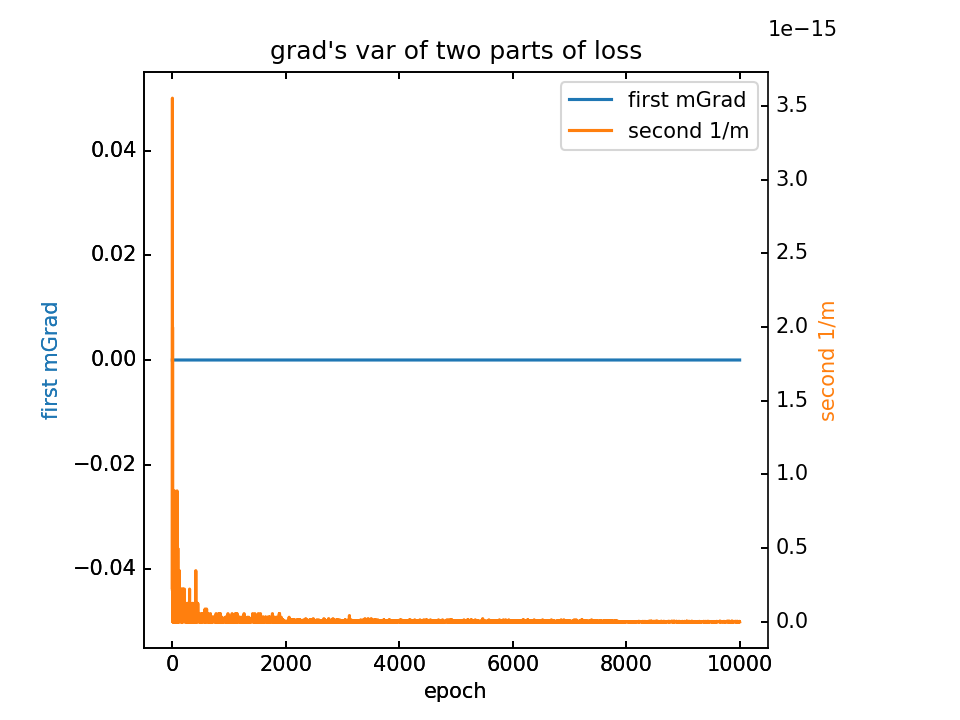
对m梯度分为两部分,蓝-λ橙。这里分别看梯度的平均值和方差
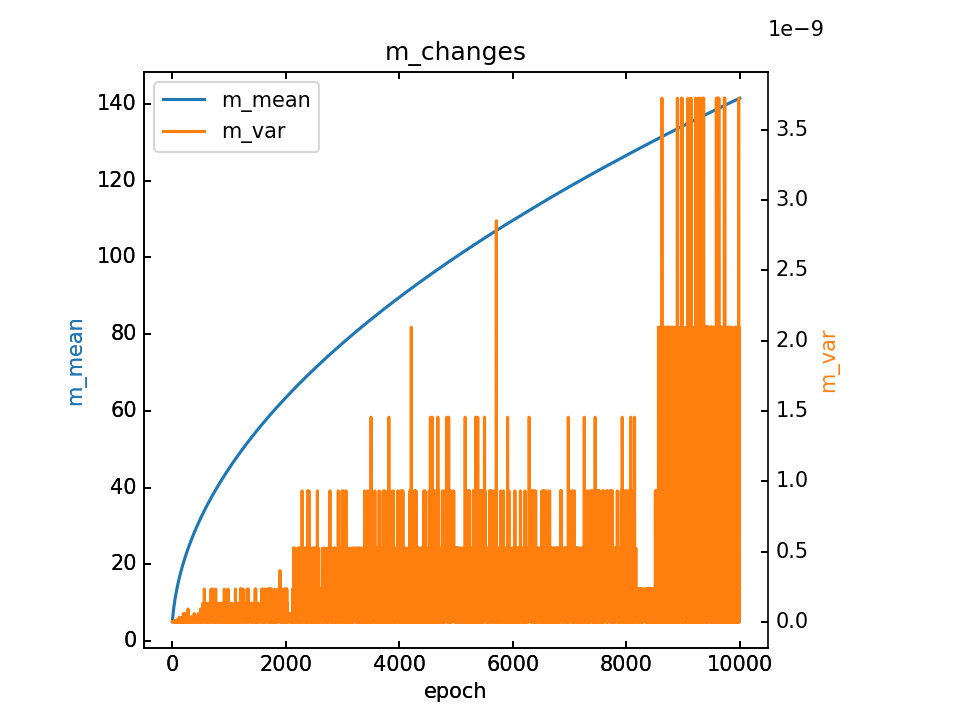
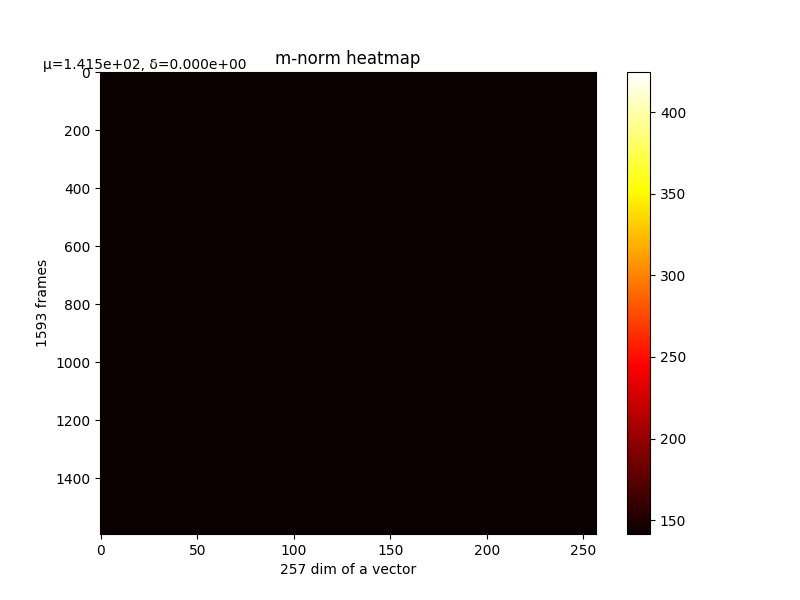
m的变化和最终m,详细

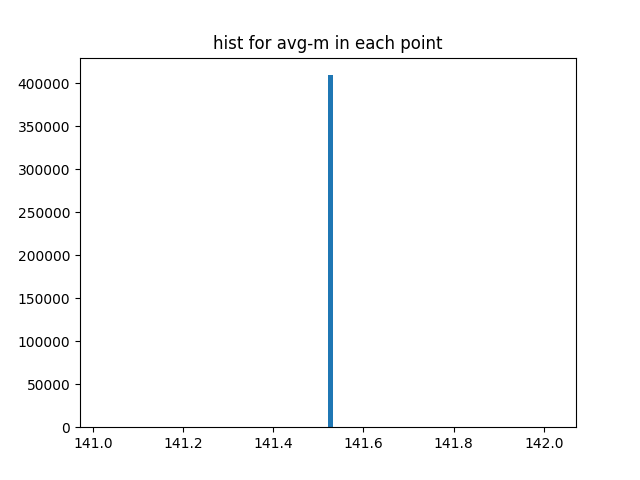
最后一层的梯度和m分布直方图
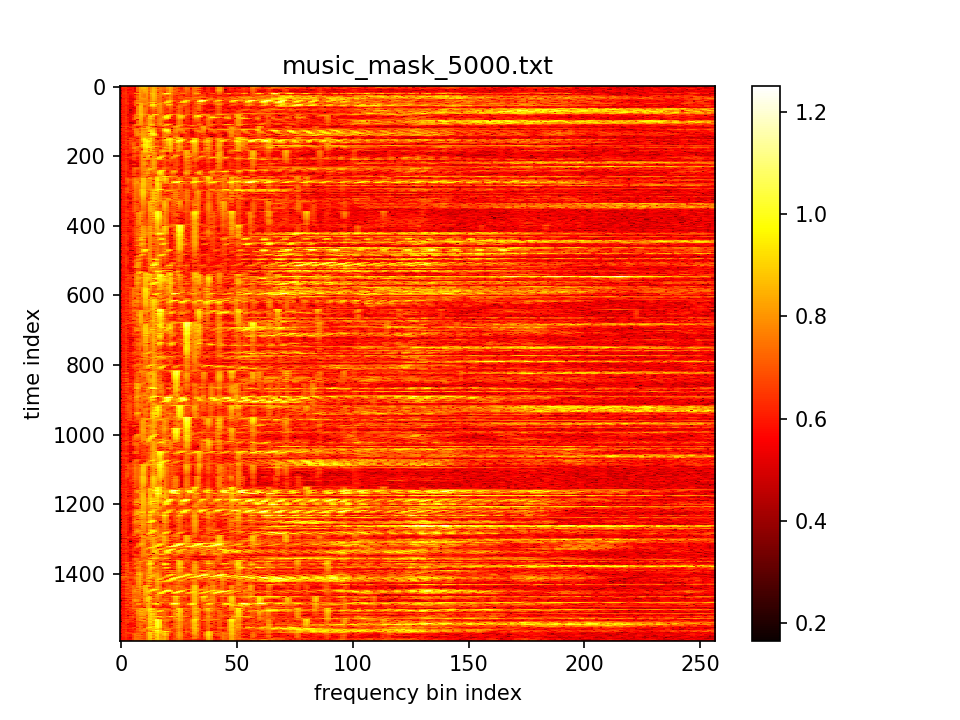
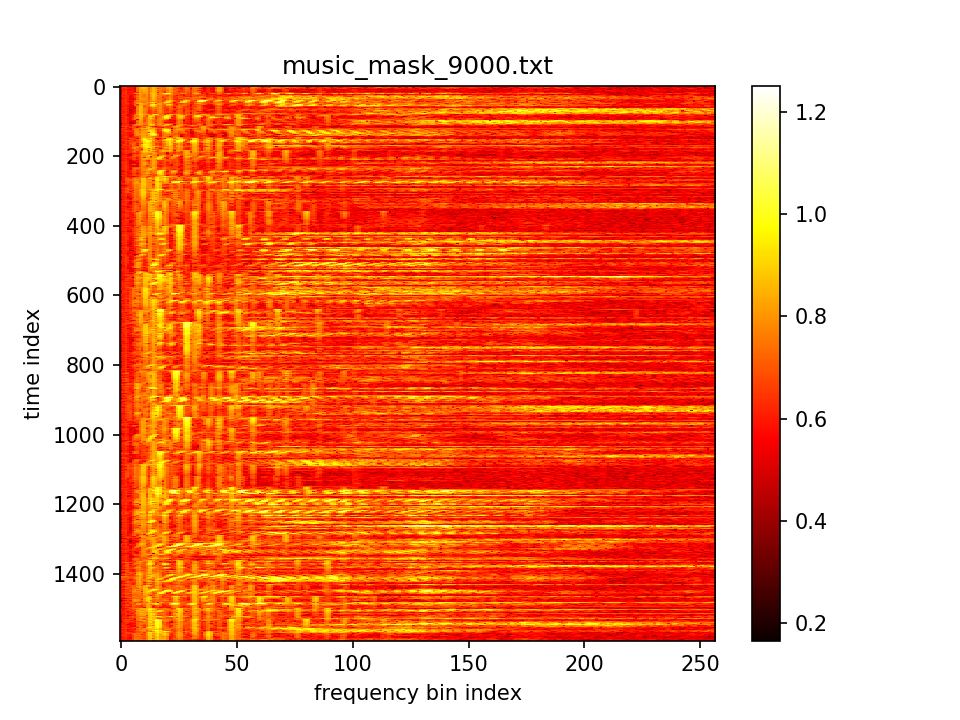
最后输出在各个维度的分布:
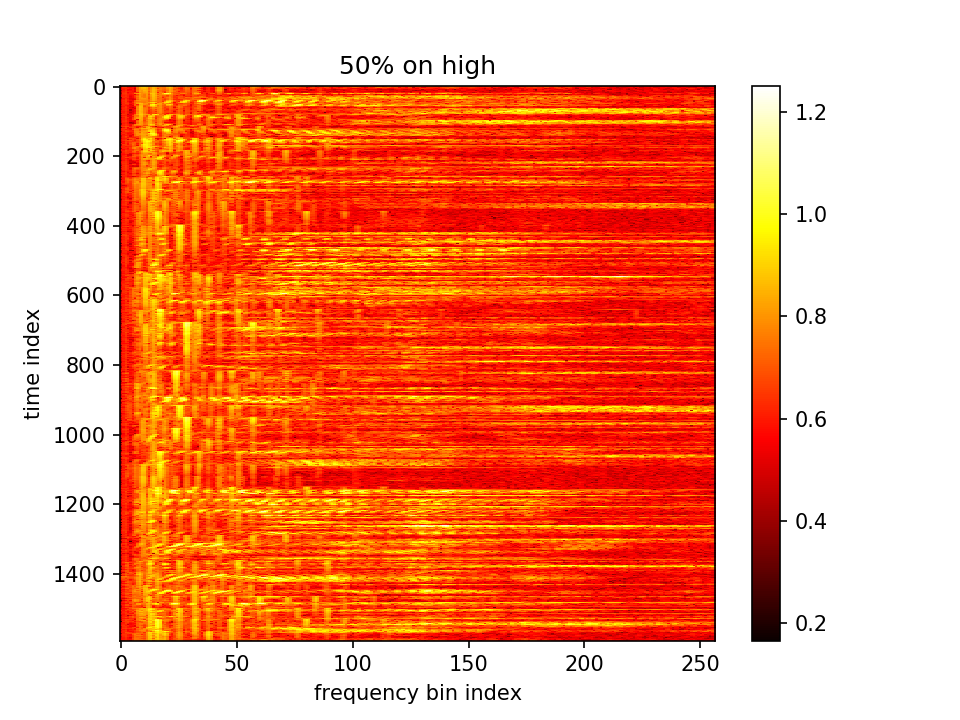


这一组又有较大问题。所有m的值都一样了,和加一层relu有关。还需要继续调整网络结构和调参。