对feature map softmax方法修改,并调整λ
1.一个bug
之前我们在对最后一层feature map处理时,想先抽出有效的26维,softmax之后再放回去,然后乘一层0对无用的5维置零。如下代码:
fl::Variable addoutput(output_arr,true);
auto tmp = addoutput(af::seq(2,27),af::span,af::span,af::span);
auto softmax_tmp = fl::softmax(tmp,0);
addoutput(af::seq(2,27),af::span,af::span,af::span)=softmax_tmp;
af::array wgt = af::identity(31, 31); // numClasses are 31 tokens
wgt(0, 0) = 0;
wgt(1, 1) = 0;
wgt(28, 28) = 0;
wgt(29, 29) = 0;
wgt(30, 30) = 0;
auto addweight = fl::Variable(wgt, true);
auto softmax_add_output = fl::matmul(addweight, addoutput);
这一段代码编译不会报错,但是将变量抽出来看后发现问题:第2、3行有正确计算26维的tmp的softmax结果softmax_tmp,但是第4行的赋值并没有成功,即addoutput的值仍然和第一行的一样。
具体原因我还在看Arrayfire的文档。现在改成不用后面的置零操作,直接将26维作为final输出,并计算preOutput和trueOutput之间的L2距离。
整体方法仍未变:横着对每个token对应的vector除以各自标准差,然后取出有效的26维,竖着对每个时间帧进行softmax。代码如下:
std::vector<int> axes1{1};
fl::Variable tmpaddOutput = fl::sqrt(fl::var(output, axes1));
tmpaddOutput = fl::tileAs(tmpaddOutput, output);
fl::Variable addoutput = output/tmpaddOutput;
auto tmp = addoutput(af::seq(2,27),af::span,af::span,af::span);
auto softmax_add_output = fl::softmax(tmp,0);
2.一些结果
-
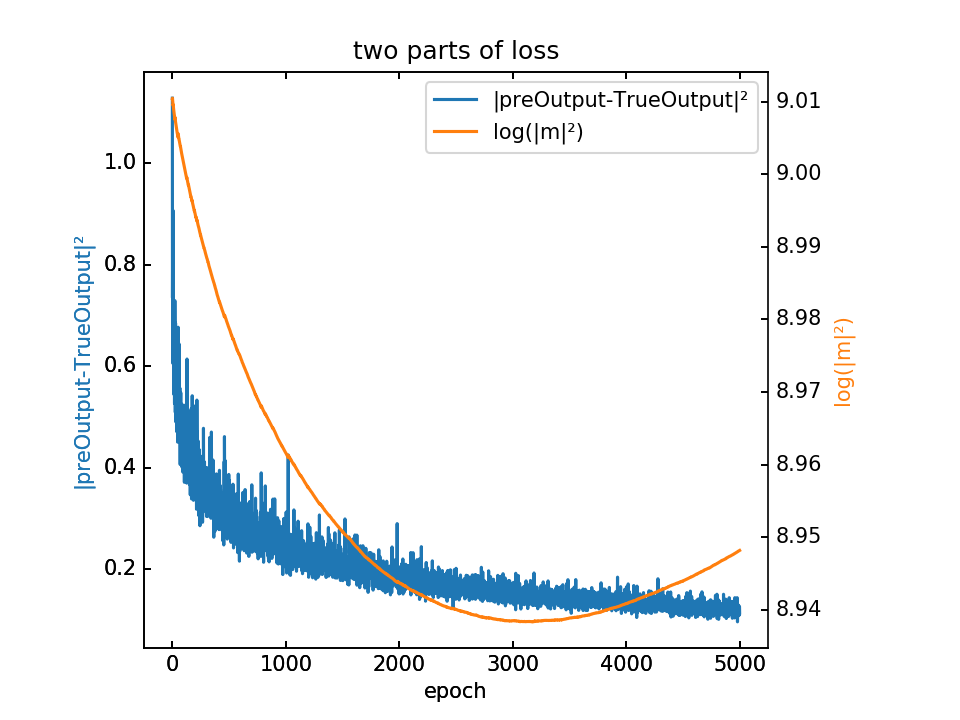
- λ=100,epoch=50000,lr=0.001
之前一直用的5000个epoch,现在换成用50000个epoch,训练时间需要将近两钟头。
可以看m的结果,如下图:
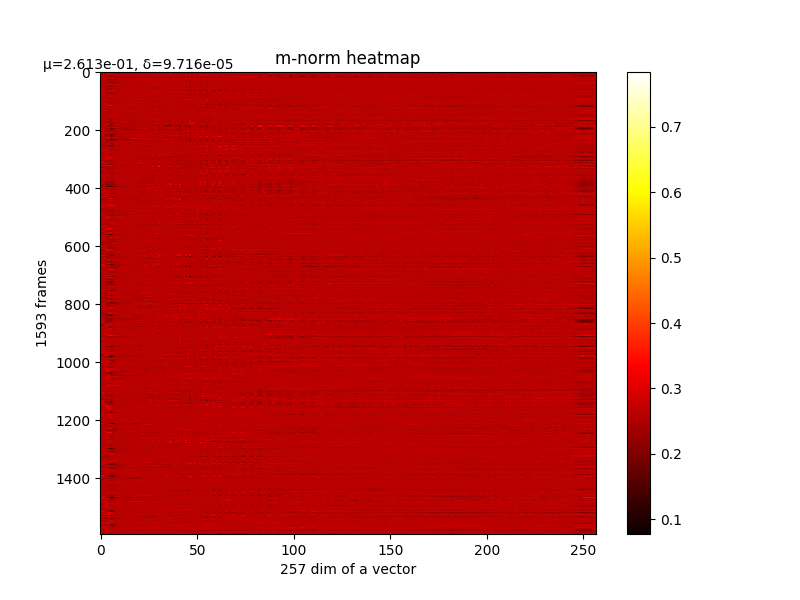
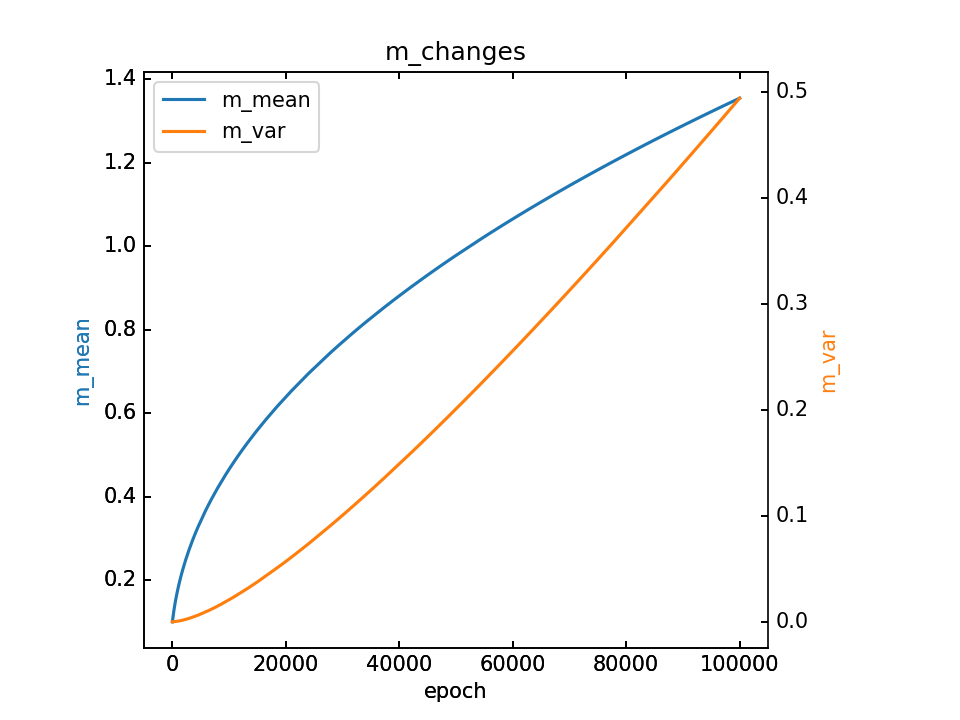
m的结果
但是查看loss我们发现,还没有收敛,如下图:
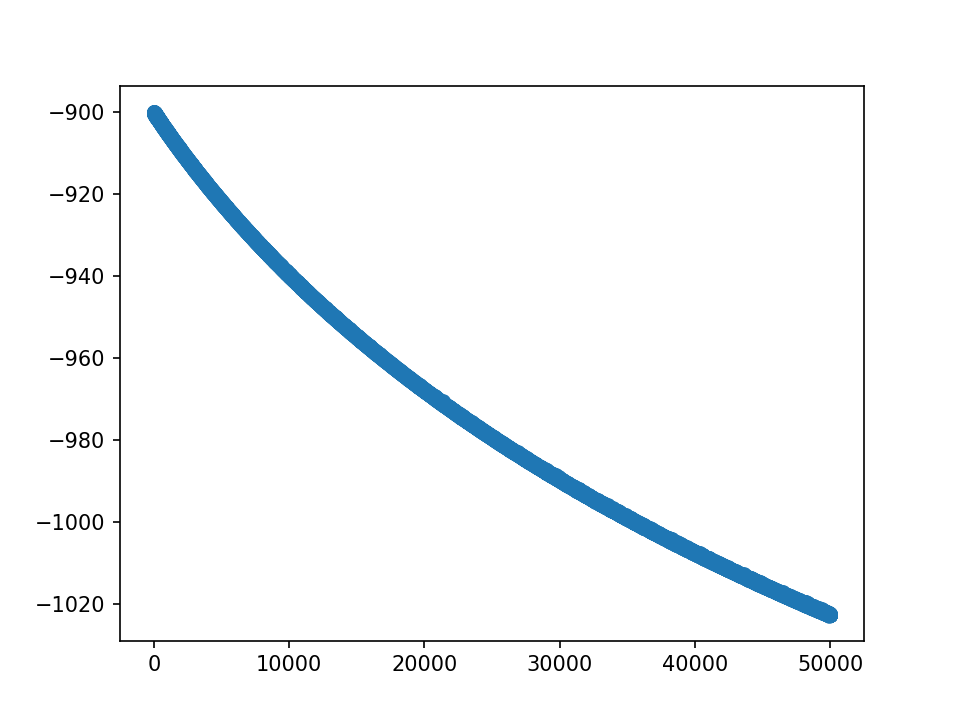
loss的值负很大,因为λ=100,而后一项的值相对大一个数量级
留下m小的点、m大的点置零:
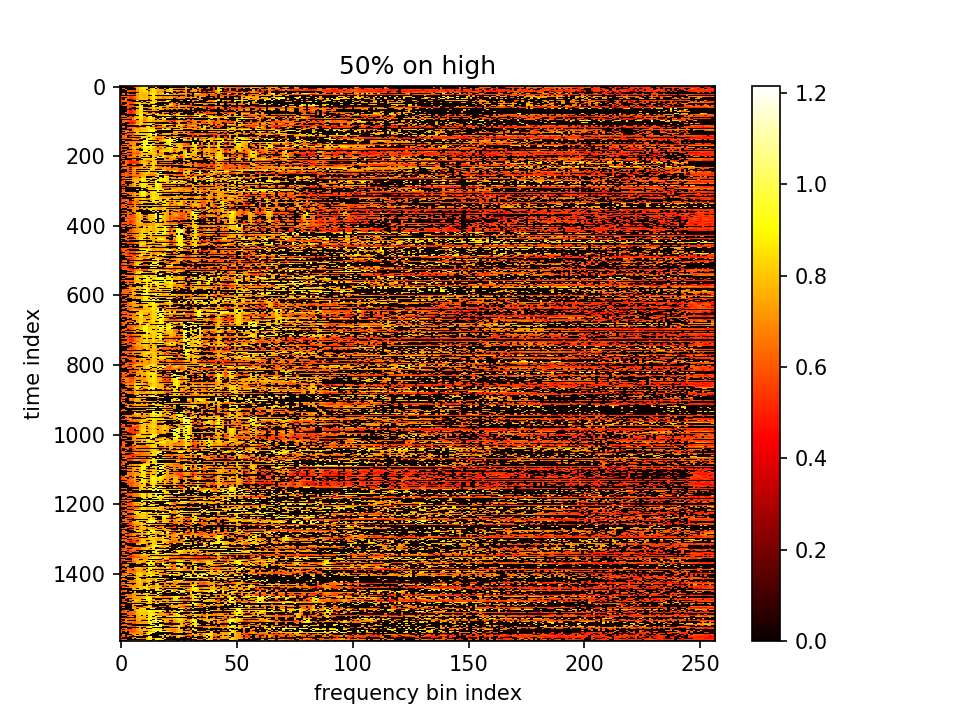
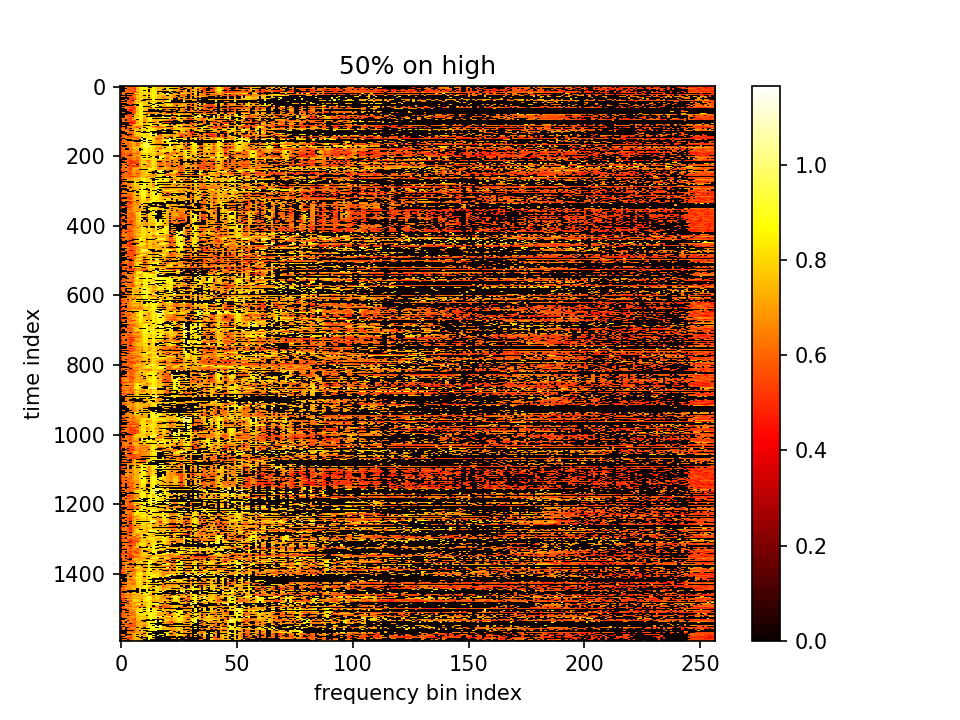
留下m大的点、m小的点置零:
于是我们把λ调回10,并且增大100倍lr=0.1(中间十倍lr=0.01也试过,仍不收敛也没有震荡)
-
- λ=10,epoch=50000,lr=0.1
可以看m的结果,如下图:
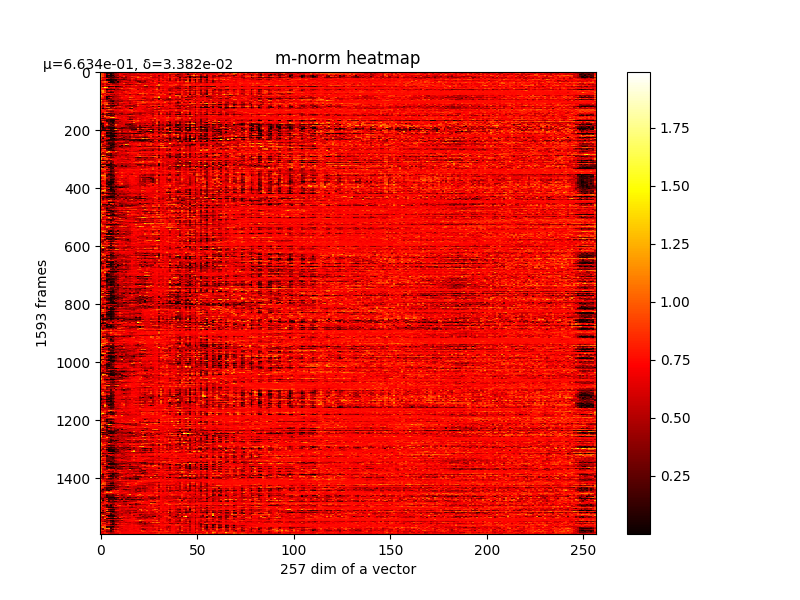
m的结果
但是查看loss我们发现,还没有收敛,如下图:
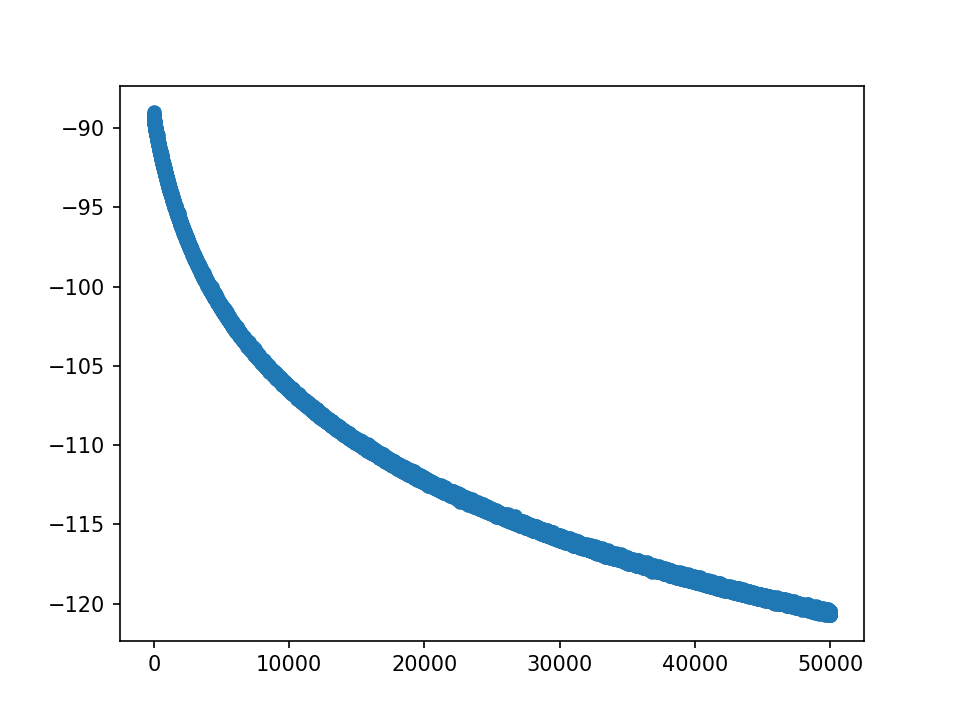
仍没有收敛。并且可以看到λ调小10倍后,loss也差不多减小的10倍,说明后一项在数值上占主导
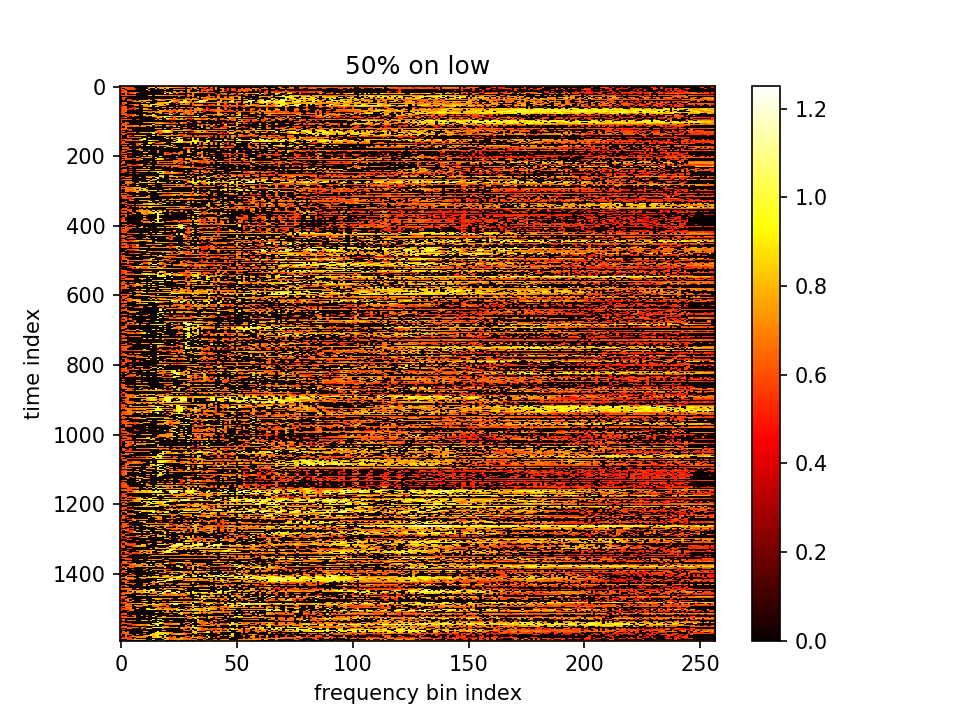
留下m小的点、m大的点置零:
留下m大的点、m小的点置零:

–
- λ=10,epoch=100000,lr=0.5
可以看m的结果,如下图:
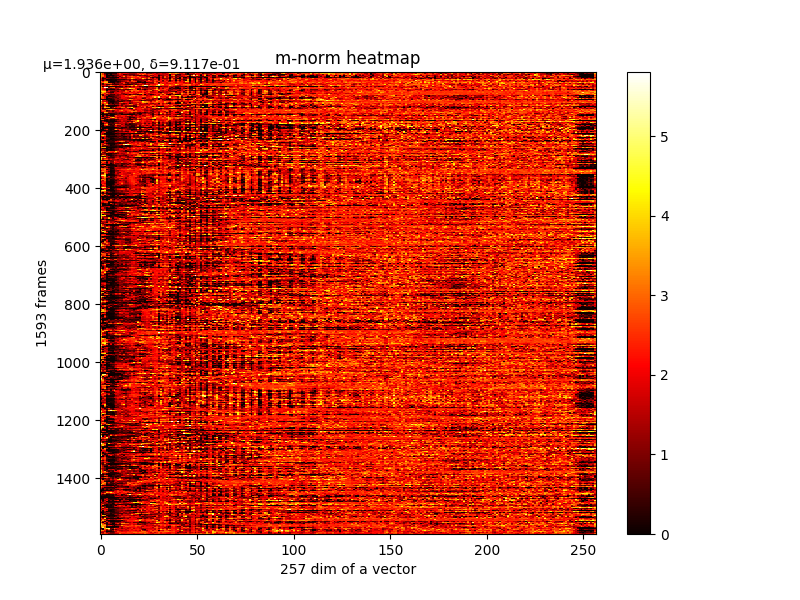
m的结果
loss:
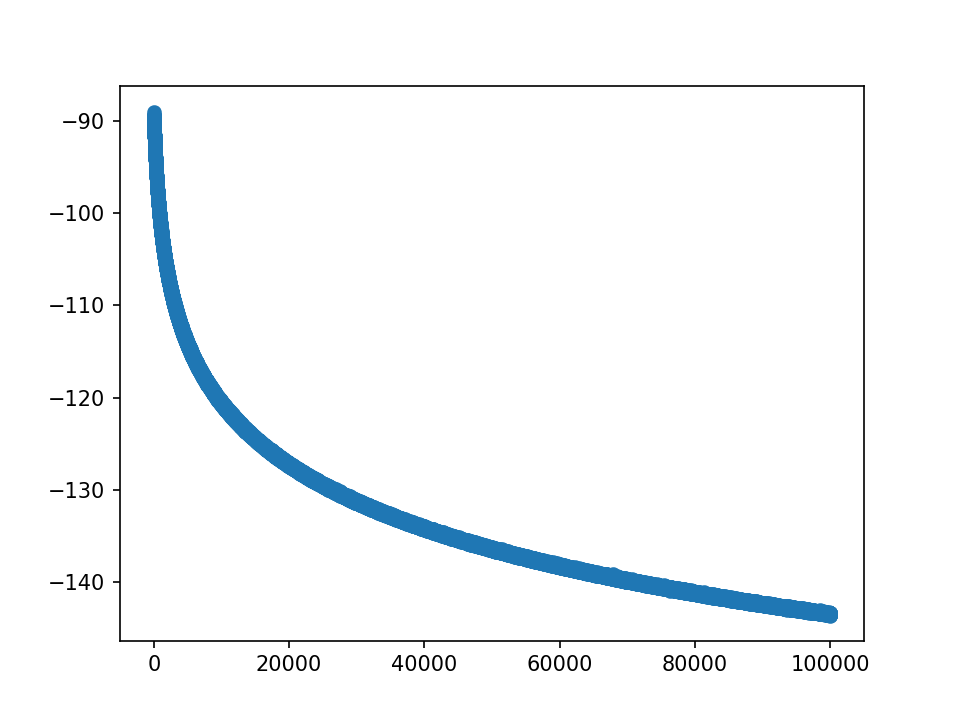
lr到0.5,即500倍,仍未完全收敛
留下m小的点、m大的点置零:
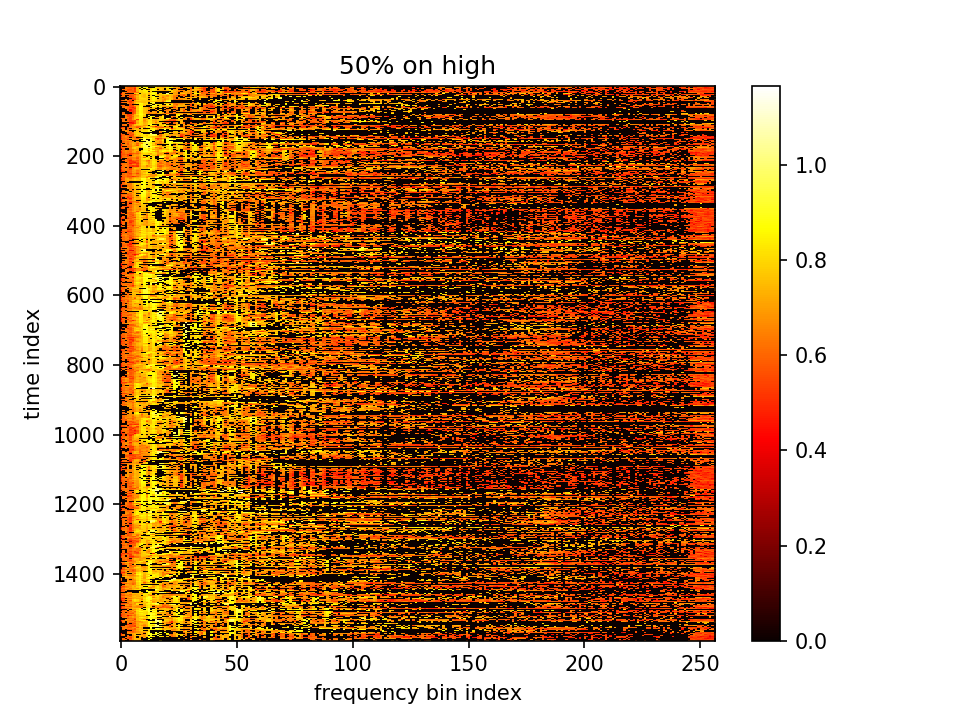
留下m大的点、m小的点置零:
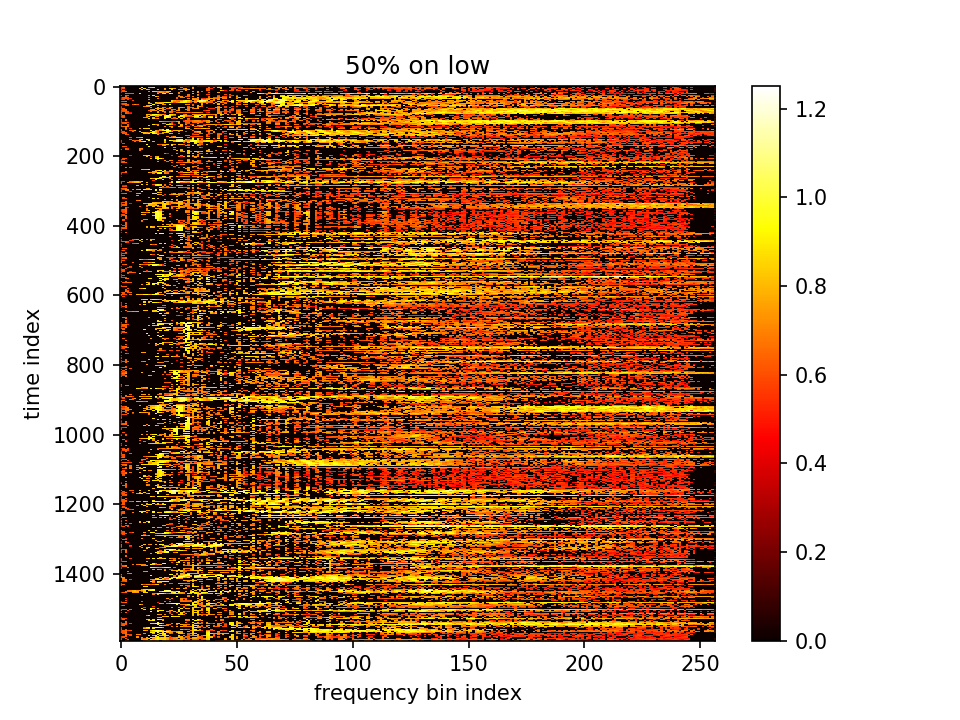
-
- λ=10,epoch=100000,lr=1.0
可以看m的结果,如下图:
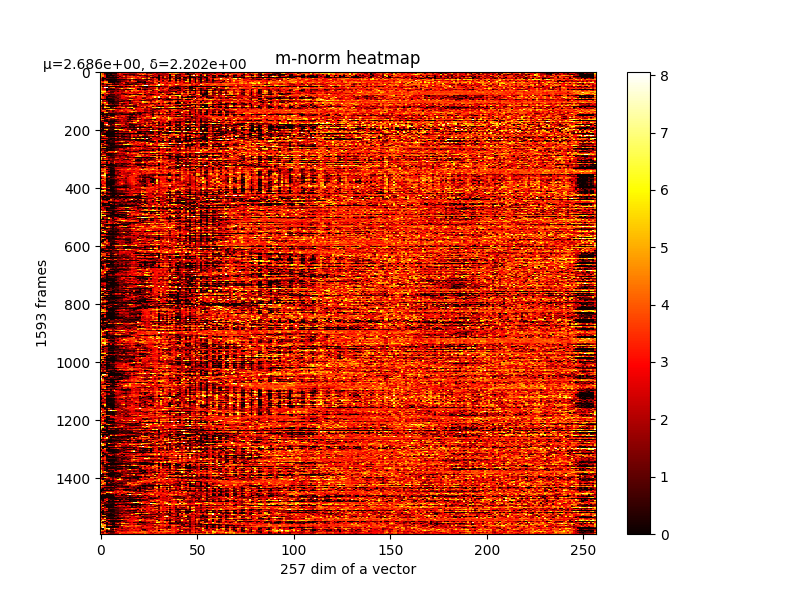
m的结果
loss:
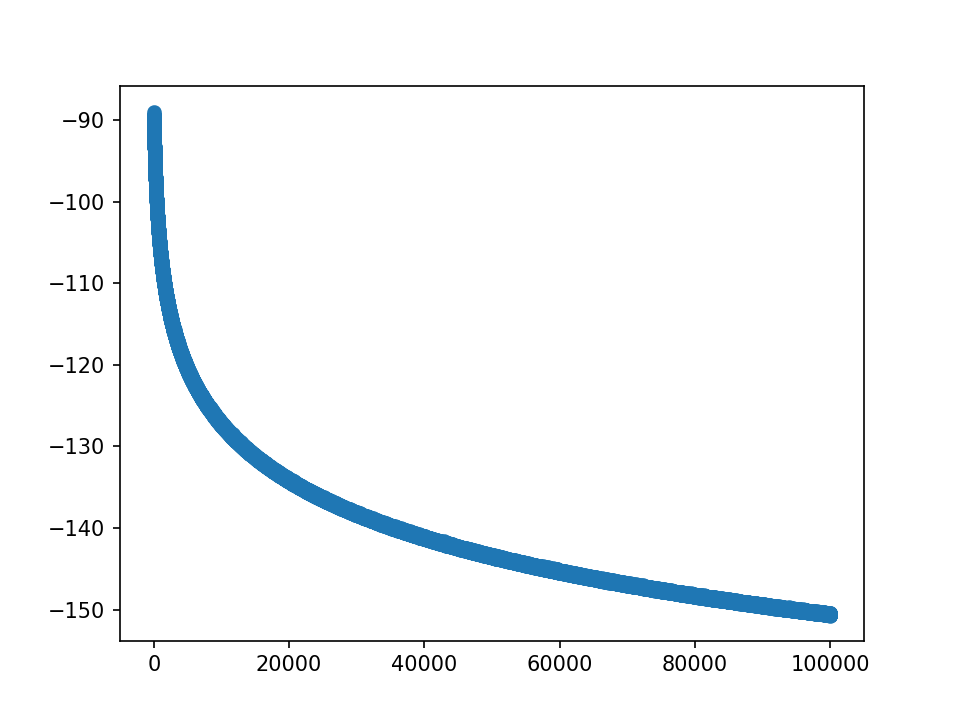
lr到1.0,即1000倍,仍未完全收敛
留下m小的点、m大的点置零:
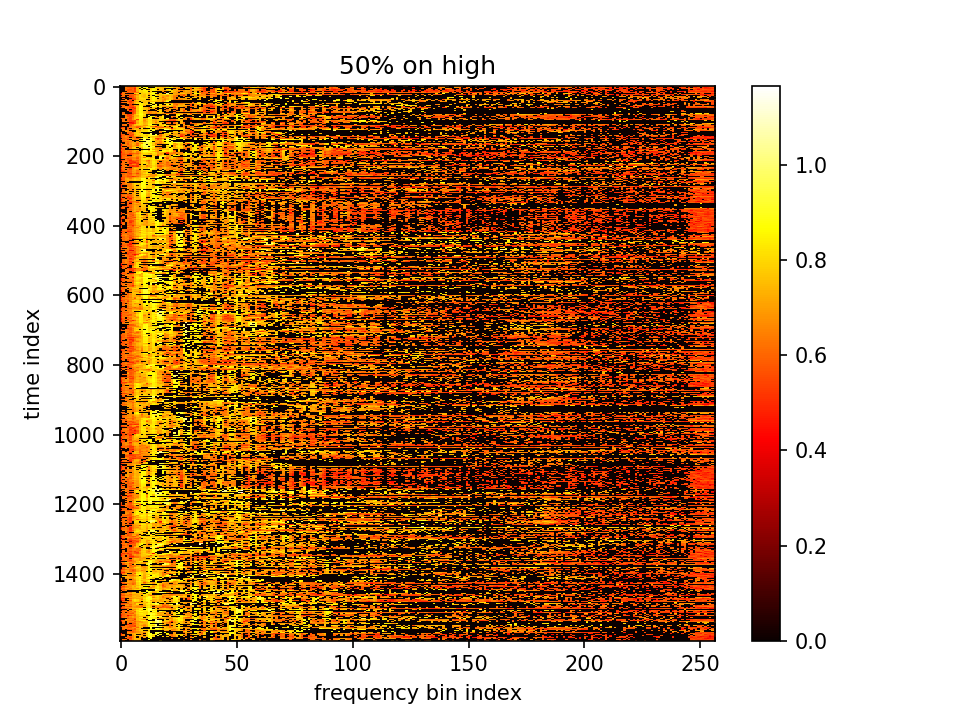
留下m大的点、m小的点置零:
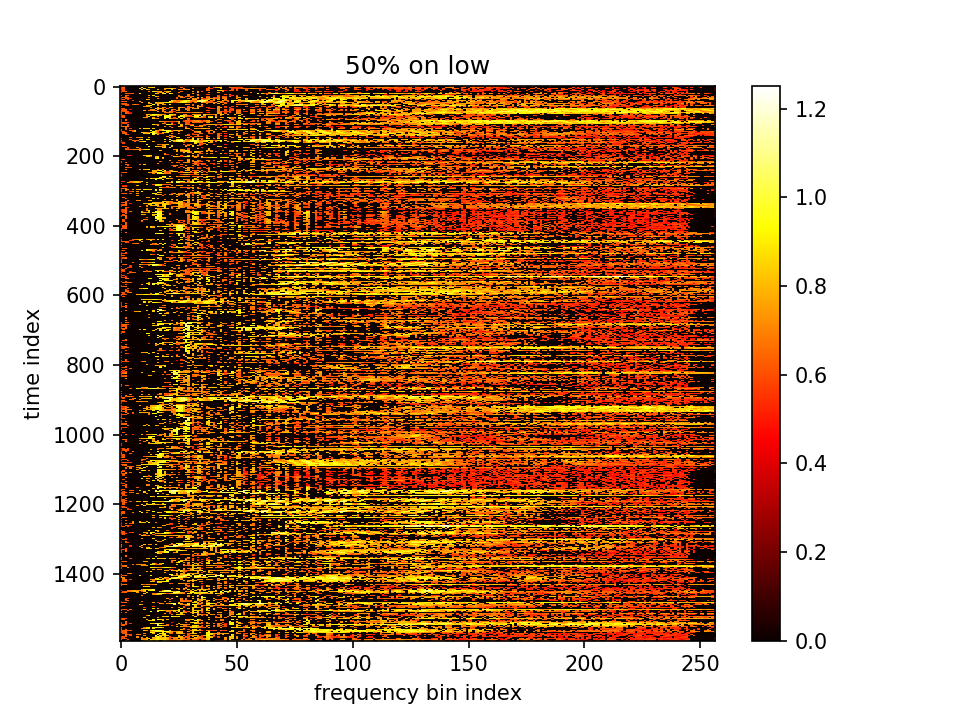
-
- λ=0.1,epoch=5000,lr=1.0
可以看m的结果,如下图:
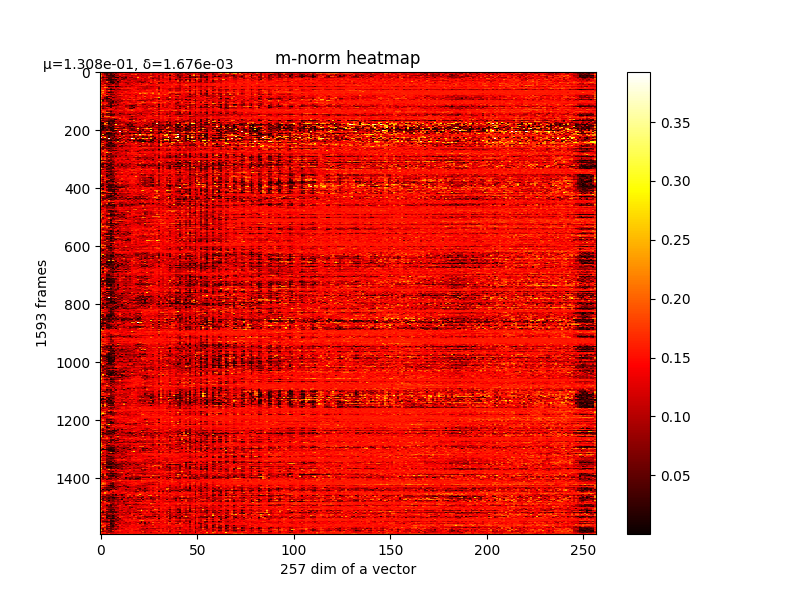
m的结果
loss:
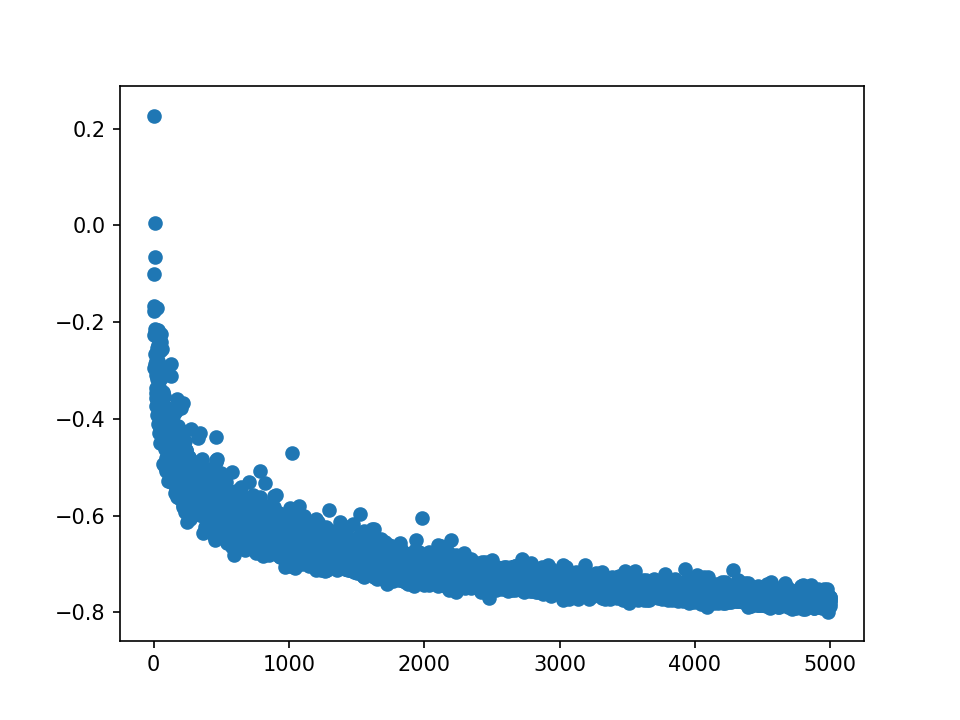
lr到1.0,即1000倍,仍未完全收敛
留下m小的点、m大的点置零:
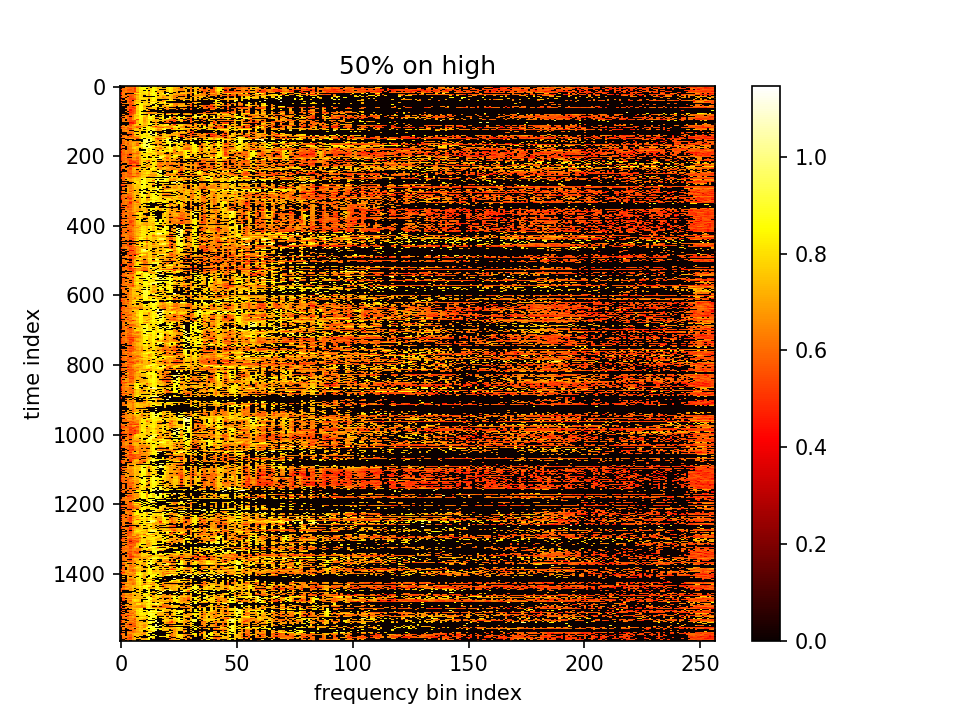
留下m大的点、m小的点置零:

值得注意的是,λ取0.1之后,两部分loss和之前(见下一部分)出现了不同,并且m的均值在一直变小。
仔细听前面几组,感觉仍然是反的…
3. 对λ选择的思考
目前 loss=|preOutput-trueOutput|²-λ*log(|m|²)
auto f_L2 = fl::norm(softmax_add_preOutput - softmax_add_output, {0,1});
auto m_L2 = af::norm(m); //double
auto myloss = f_L2 * f_L2;
float totloss = myloss.scalar<float>() - lambda * std::log(m_L2 * m_L2);
梯度算法则是:
auto sigma2 = stdev * stdev; //trInput的标准差
auto dy = trueInput.grad().array(); //T x K
auto dsigma2 = af::sum<float>(dy * (trInput - mean) * (-0.5) * std::pow(sigma2, -1.5));
auto dmu = af::sum<float>(dy * (-1.0/std::pow(sigma2, 0.5))) + af::sum<float>(-2 * (trInput - mean)) * dsigma2 / (T * K);
auto dx = dy / std::pow(sigma2, 0.5) + dsigma2 * 2 * (trInput - mean) / (T * K) + dmu / (T * K);
af::array xGrad = af::transpose(dx); // K x T x 1 x 1
auto midGrad = epsilon * epsilon * m + epsilon * pre_sample[kFftIdx];
auto xGradm = midGrad / backinput; //2K x T x 1 x 1
af::array mGrad = af::constant(0, noiseDims);
for(size_t j=0; j< 2*K; j=j+2) {
mGrad(j, af::span, af::span, af::span) = xGrad(j/2,af::span,af::span,af::span) * xGradm(j,af::span,af::span,af::span);
mGrad(j+1, af::span, af::span, af::span) = xGrad(j/2,af::span,af::span,af::span) * xGradm(j+1, af::span,af::span,af::span);
}
mGrad = mGrad - 2 * lambda * m / (m_L2 * m_L2);
m = m - mylr * mGrad;
查看totloss的两项之间的大小关系,如下图:
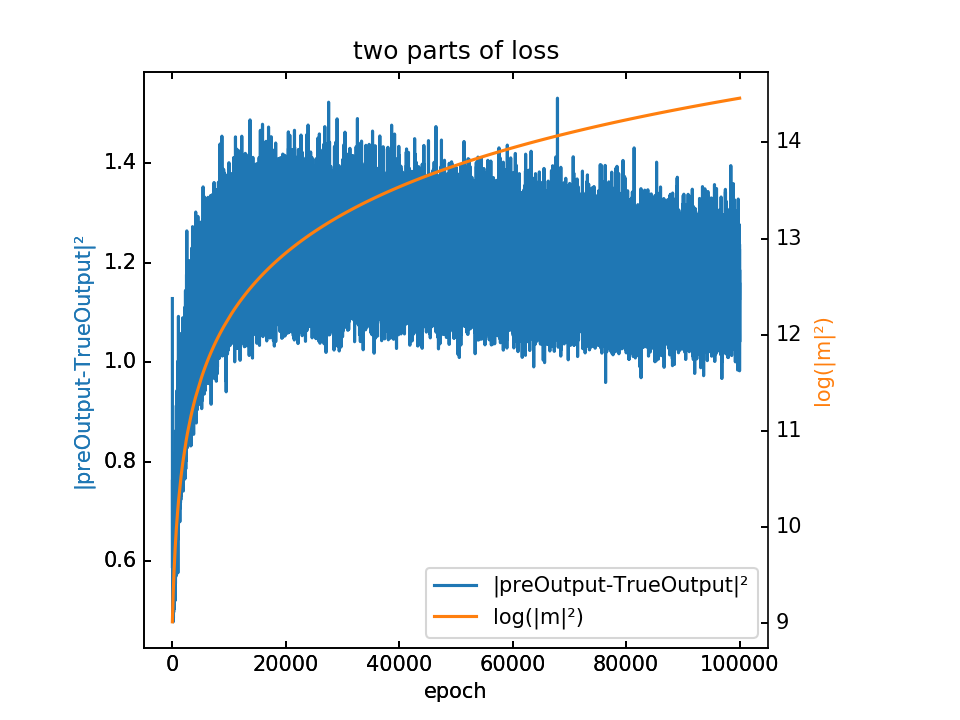
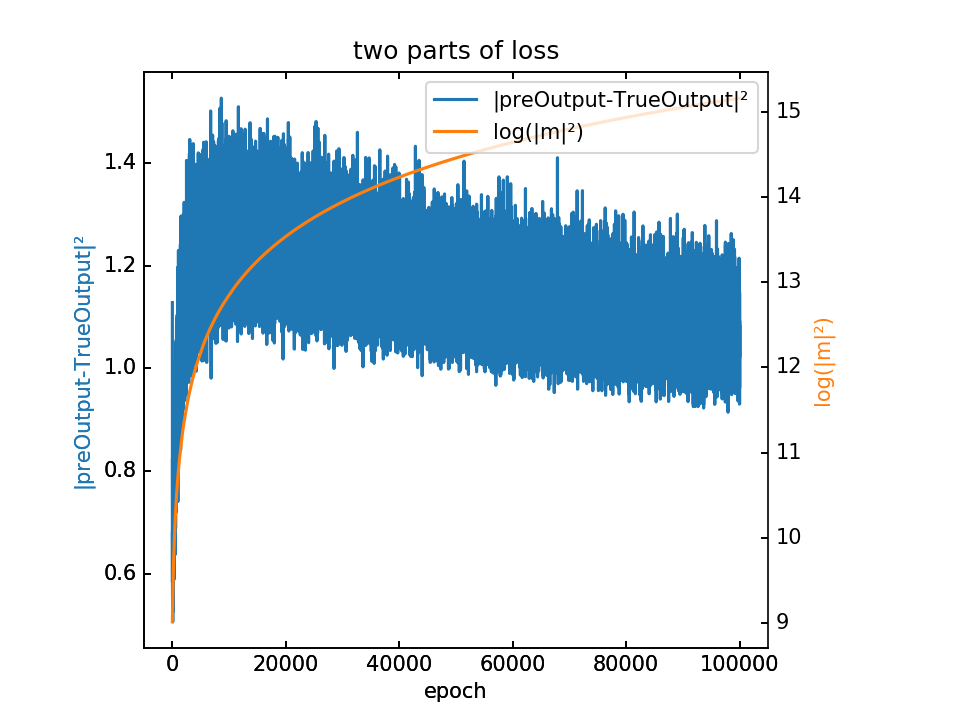
可以看出,其中第二项的数量级大概在第一项的10倍左右,那么取λ=10或100,会不会造成第二项过大,相应的第一项的影响就很小?
不过仍然还要看totloss对应的梯度,两项之间的大小关系。
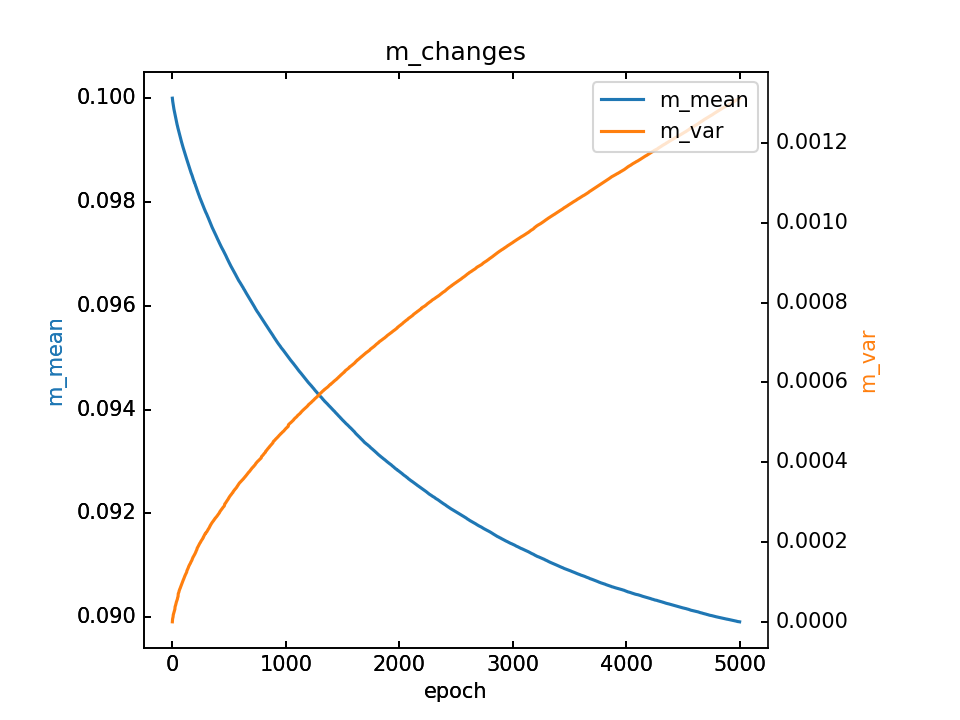
从上图也可以看出,由于m是随机取值点,震荡较大,其mean和var如下图: