前期工作回顾
简要回顾语音组的前期工作
1.m的分布
⼀条语⾳切为T帧,每一帧进行fft得到K=257维complex vector,学得的m为2K*T维(实部虚部分开储存)。
取一条语音分析,T=1042帧,对每⼀帧的complex vector的每个复数取模,得到K*T维m-norm矩阵。最初的m矩阵如下图。
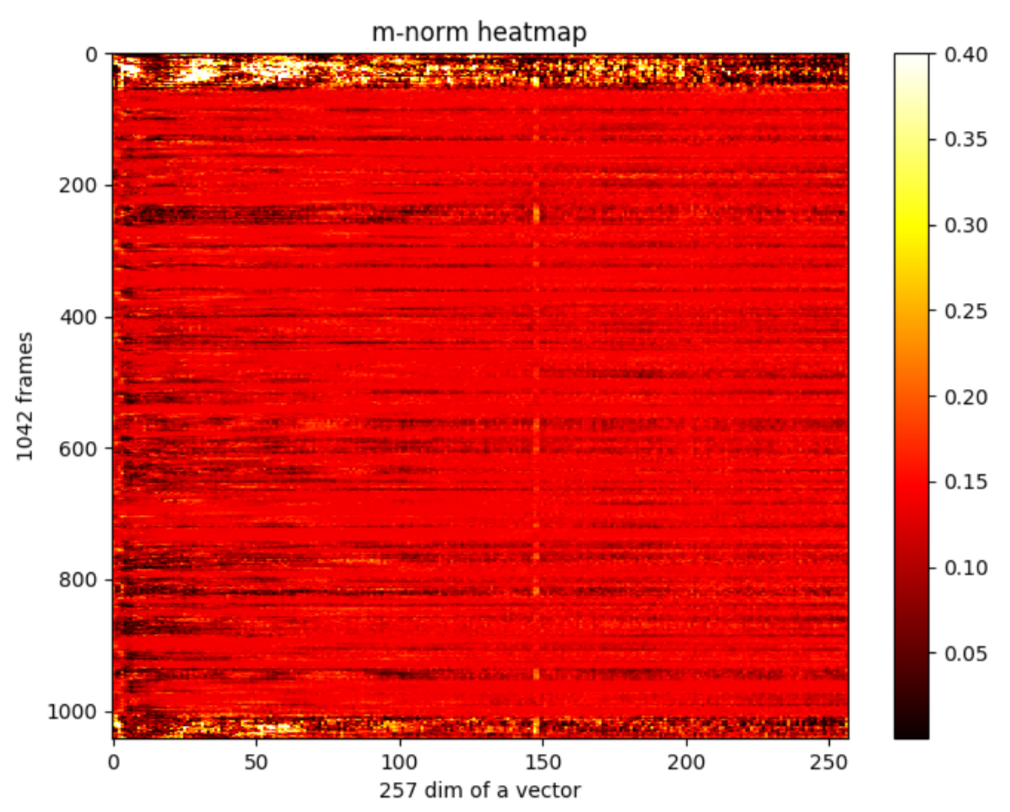
var=0.00164905895109,mean=0.133361973917
图中纤维总体呈横向,说明对某一帧来说,其在不同fft vector dim(即不同频率)上对结果的contribution都相近。也有少量量纵向纤维,⽐如150维附近的⼀一条白线,可能这个频率上的声音contribution都不大。
2.反向合成声音
w2l算法首先使用fft处理声音,再正向传入网络。我们找出m矩阵中值较大的点,认为这些点是影响较小的,将fft矩阵中对应这些坐标的点置零,再使用逆傅里叶变换ifft返回声音。
刚开始使用的ifft方法丢弃相位信息,利用迭代估算,不精确。
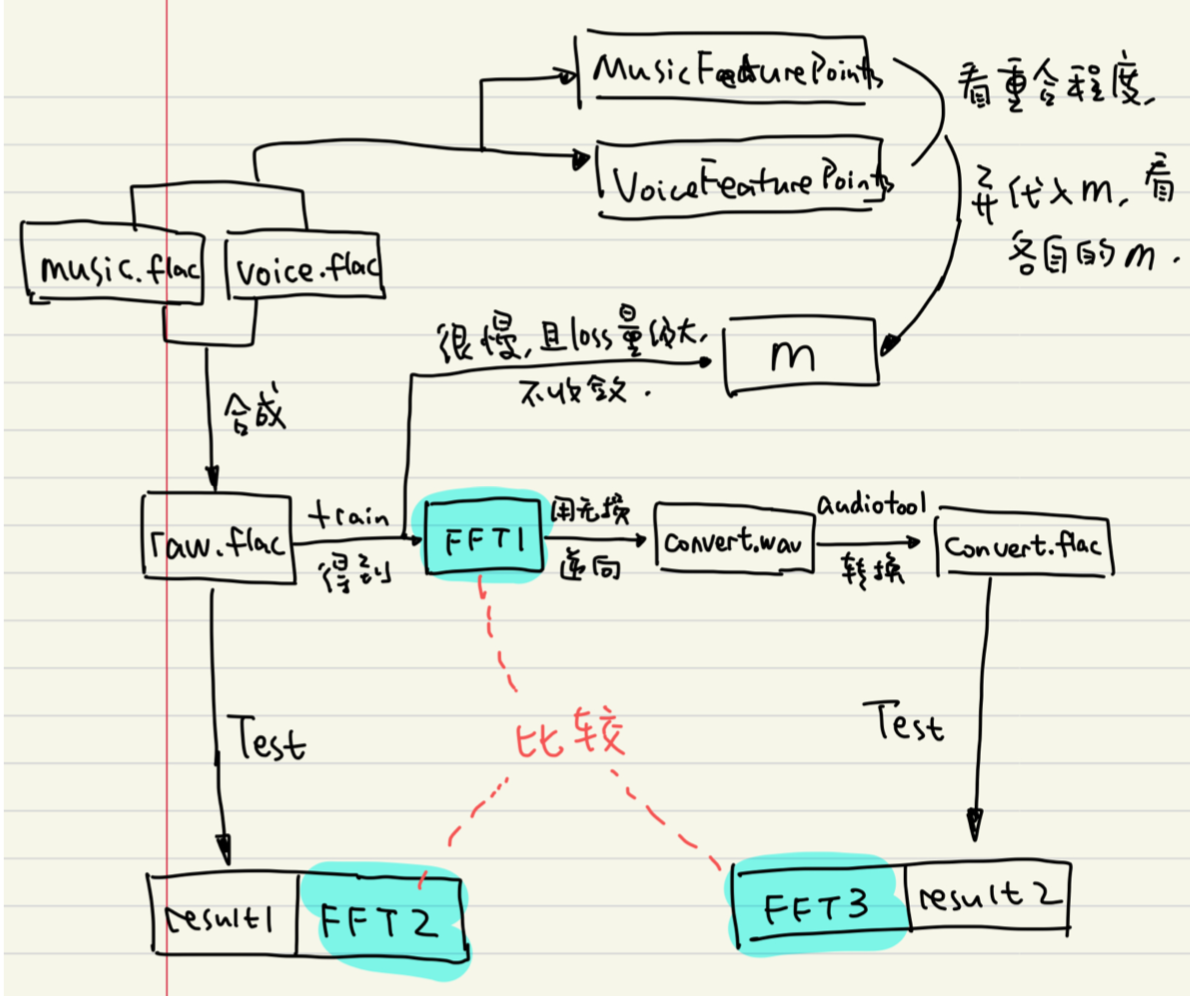
后来使用传入相位矩阵的ifft方法,排除此影响,能确保和fft是完全可逆的。同时也确定了,将fft矩阵中置零的操作,是有效的,即消音处理。
3.音乐语音合成
从网易云爬取1000首钢琴音乐,随机切片后和原始语音合成,例子如下:
人声:
音乐:
合成:
我们预期的结果是,m大的点恰好是音乐,将m大的点置零后在还原出的声音,应该主要是人声部分。
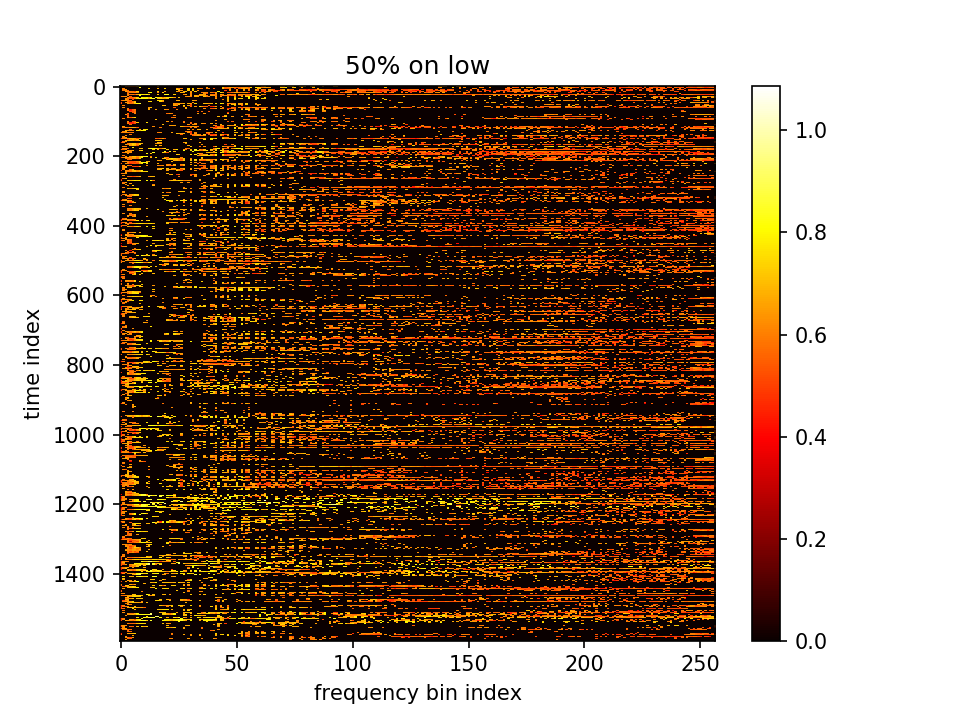
同时为了避免置零时大量人声钢琴同时置零,想查看钢琴和人声在频谱图上的分离程度有多大。将fft矩阵中,值较大的前50%点视作特征点。找到music.flac和voice.flac各自的特征点,查看他们在频谱图中的重复程度:
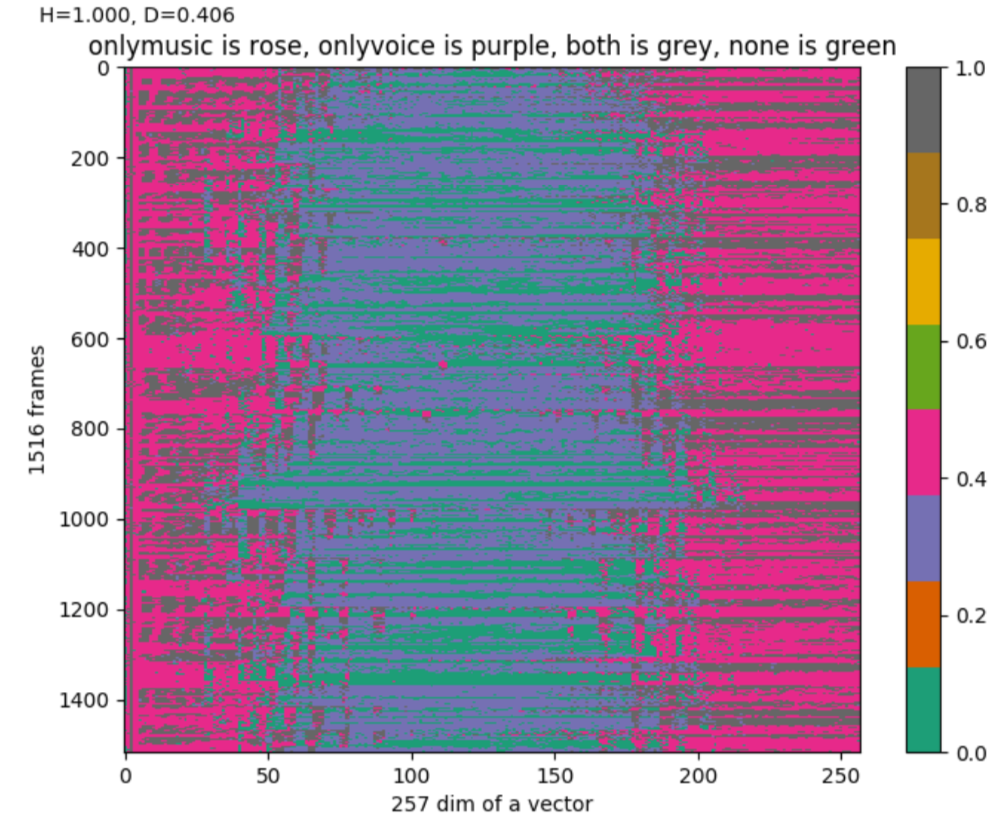
玫红:纯music,紫:纯人声,灰:都,绿:都不
发现人声的频率范围覆盖整个257维,钢琴声只在高维和低维集中分布。
为了衡量两个点集A和B的重合程度/距离,定义:
H=HausdorffDistance,
D=DiceCoefficient,
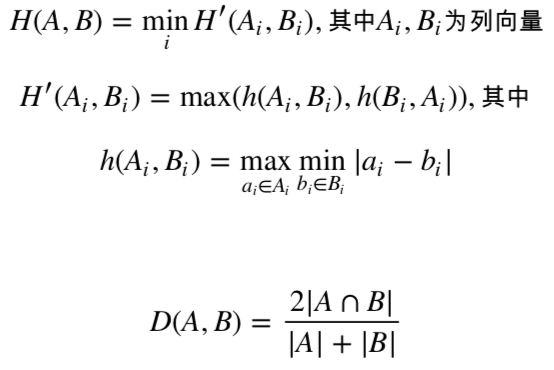
得到H=1,D=0.406(约40%重复,可接受)。则初步认为,后续出现的问题,和音乐、人声的重复没有关系。
4.结果一直是反的
初始:
将m值较大的50%点置零,留下的理应是“重要的”,实际是杂音:
将m值较小的50%点置零,留下的反而清晰:
换一个角度,统计music的特征点区域和voice特征点区域上,m的值分布:
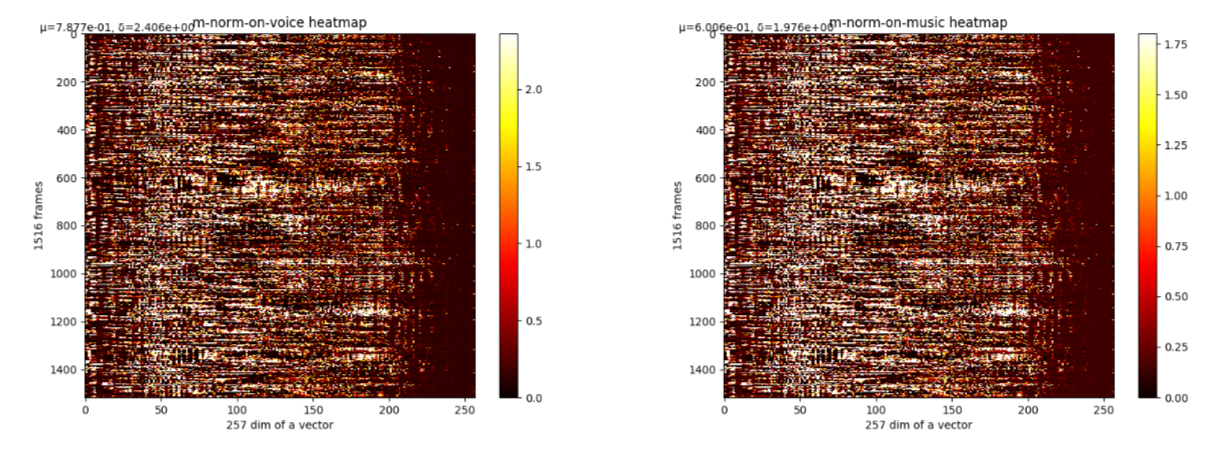
整个m的均值在0.79,⼈声区域的m均值为0.78,音乐区域的m均值为0.60。即结果还是反的
我们同样也将生成的语音进行正向测试,查看错误率。同样是,将m较大的点置零生成的声音,错误率反而更大:
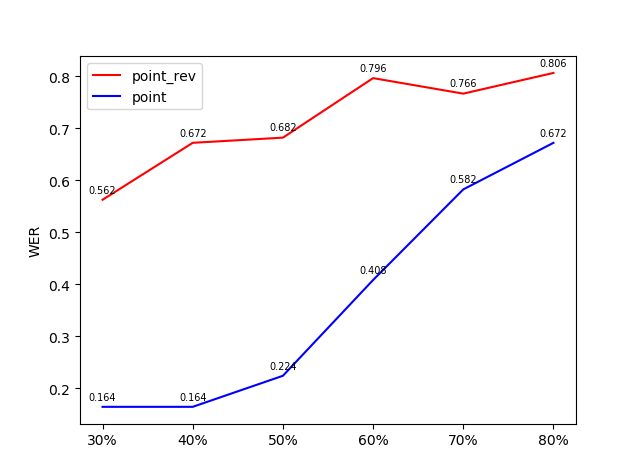
5.训练时加的噪音问题
我们考虑过,相反是否因为训练时加的噪声过大、掩盖了原声。摘出训练5000个epoch中的fft矩阵(即叠加了训练的噪声的),查看各自的均值和方差:
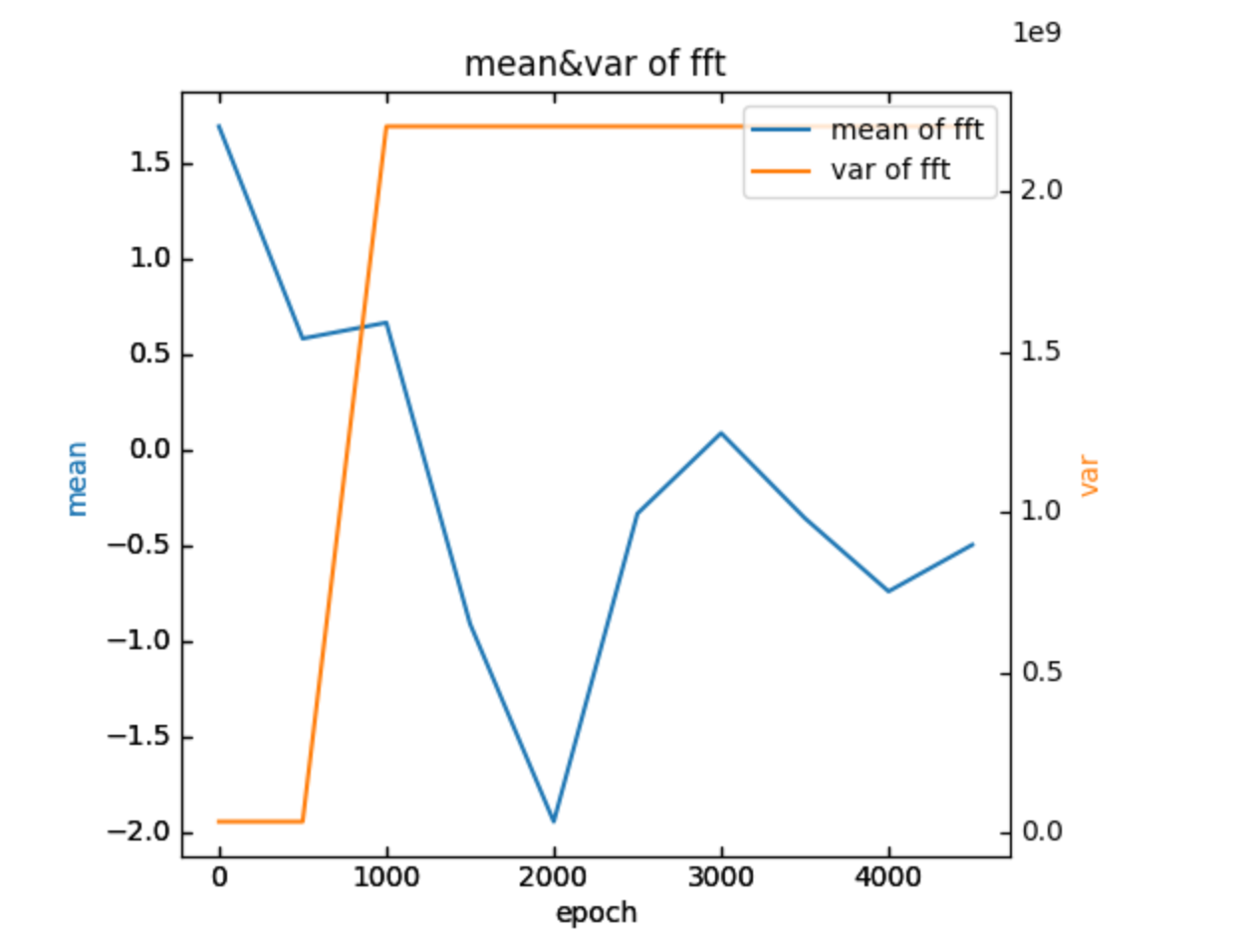
其中第0个epoch是原始的fft矩阵,可以发现,加入噪声后均值发生了较大的跳动,但是从0至第500个epoch,均值的变化还是较小的,方差也几乎没变化,这说明初始时加入的噪声相比原声并不大。但是在超过500个epoch后的训练中,方差发生了跳升,均值的变化也有加剧。
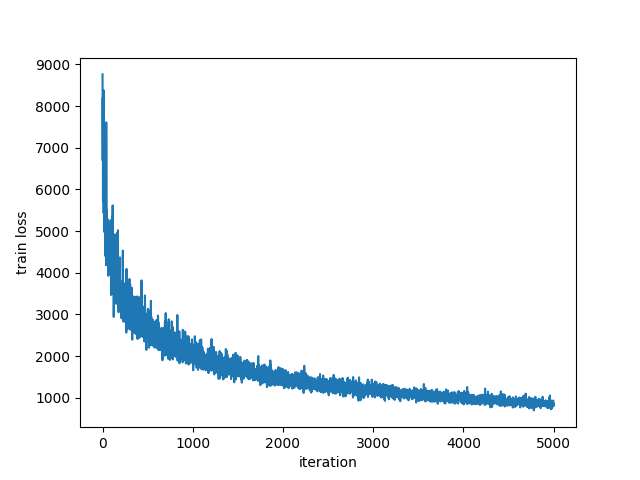
尽管听上去都只是加了一些杂音,并且loss看上去也合理收敛了,但噪音造成的这种大变化到底因为什么?我认为这里仍需要讨论。
6.空语音、占位符的存在
网络的fc层输出是一个31*T维的矩阵,再传入语言学模型。这个output矩阵,代表对T维的时间帧,每一帧在31个token的可能性。这31个token中,只有26个英文字母,剩下5个是停顿、标点、语素间隔等。
首先搞清楚31个维度分别对应哪些token:
tkn_dict={0: '|', 1: "'", 2: 'a', 3: 'b', 4: 'c', 5: 'd', 6: 'e', 7: 'f', 8: 'g', 9: 'h', 10: 'i', 11: 'j', 12: 'k', 13: 'l', 14: 'm', 15: 'n', 16: 'o', 17: 'p', 18: 'q', 19: 'r', 20: 's', 21: 't', 22: 'u', 23: 'v', 24: 'w', 25: 'x', 26: 'y', 27: 'z', 28: '.', 29: '.', 30: '.'}
...
tkn_mtx=np.loadtxt(pre,comments=['p','[','#','l'])
tkn_mtx=tkn_mtx.T
with open(writedir,'a')as f:
f.write('pre:\n')
for frame in tkn_mtx:
ind=np.argmax(frame)
f.write(tkn_dict[ind])
f.write('\n\n')
...
比如传入happy的声音:
模型输出的识别结果是hat|pe|i;而取出output矩阵并寻找每一帧的最大值后,打印出结果为|||||||||||||||||||hat|||||||||pe|i|||||||||||||||,说明token和index是可以对上的。后面步骤也可说明。
考虑到这些占位符在各帧中出现的次数非常多,而和音乐合成后,往往这些区域就是音乐声,所以可能导致音乐声“更重要”。
需要将这些占位符维度置零,使得在反向传播中乘数为0,无效。
尝试过不同的置零方法,因为有可能这些占位符维度置零后,剩下的维度相对都很小且差不多,失去反向传播的意义。
目前使用的方法是:
- 1.首先横着,对31个token,对应的时间向量,除以各自标准差
auto output = ntwrk->forward({trueInput}).front();
auto output_arr = output.array();
af::dim4 outputDims = output_arr.dims();
int tokendim=outputDims[0];
std::vector<int> axes1{1};
tmpaddOutput = fl::tileAs(tmpaddOutput, output);
fl::Variable addoutput = output/tmpaddOutput;
/*
for (size_t j = 0; j < tokendim; ++j){
auto framestdev=af::stdev<float>(output_arr(j,af::span,af::span,af::span));
output_arr(j,af::span,af::span,af::span)=output_arr(j,af::span,af::span,af::span)/framestdev;
}
*/
- 2.再竖着,对T个31维token向量,和31个T维字母向量,依次做softmax
auto softmax_output = fl::softmax(addoutput,1);
softmax_output = fl::softmax(softmax_output,0);
- 3.置零
af::array wgt = af::identity(31, 31); // numClasses are 31 tokens
wgt(0, 0) = 0;
wgt(1, 1) = 0;
wgt(28, 28) = 0;
wgt(29, 29) = 0;
wgt(30, 30) = 0;
auto addweight = fl::Variable(wgt, true);
auto softmax_add_output = fl::matmul(addweight, softmax_output);
- 4.计算loss
float lambda = 10;
//float lambda = 100;
auto f_L2 = fl::norm(softmax_add_preOutput - softmax_add_output, {0,1});
auto m_L2 = af::norm(m); //double
auto myloss = f_L2 * f_L2;
//auto firloss = fl::MeanSquaredError();
//auto myloss = firloss(output, preOutput);
float totloss = myloss.scalar<float>() - lambda * std::log(m_L2 * m_L2);
结果如下:
原语音的ground-truth如下:
t h a t | h a d | i t s | s o u r c e | a w a y | b a c k | i n | t h e | w o o d s | o f | t h e | o l d | c u t h b e r t | p l a c e | i t | w a s | r e p u t e d | t o | b e | a n | i n t r i c a t e | h e a d l o n g | b r o o k | i n | i t s | e a r l i e r | c o u r s e | t h r o u g h | t h o s e | w o o d s | w i t h | d a r k | s e c r e t s | o f | p o o l | a n d | c a s c a d e | b u t | b y | t h e | t i m e | i t | r e a c h e d | l y n d e ' s | h o l l o w | i t | w a s | a | q u i e t | w e l l | c o n d u c t e d | l i t t l e | s t r e a m
取出每一帧,索引probability最大的字母维度,如下:
...............||..att..||hh.a.d....i.t.......|.s.oouurc.e...||.a.....w.a.y.......|||b.a.ck..|..inn||the.||w..o..dd.s||.off|tthe||.o.l..d....||.c.o.fh.....b.eritt......pl.a.c.e........................................||..i.t..|wwaas.|..rre...p.uu.t....e.d||t.o||b.e||.an..||..ann....ttric...guett....i..||hhead.....ll.o.ng.......||brro.kk..|..i.n.|i.ts||..ear....lhy||..a..||c.oourrse...|through|tho...sss.||.w.o..dd..s....................||wwiithh.....||d.a.rrkk...........||.s.e.c....rreit.ss||.off.....|.p..o..l.....||.andd...||.c.a.st........g.a.ddee.................................||b.u.t.....||bbyy..|tthe.||tt.i.m.e.|.a.t..|.r.eachhe.d..|..l.a.ne....ss..|.h..o.l......oww.....|||.itt.||wwass||.a..|.qquui.......e.t.......||ww.e.l....||c.on....d.u.ct......edd.||l.itt.llee...||sttree.t...........||
将output矩阵经过上述操作后,(即实际参与计算loss和反向传播的矩阵),其对应的字母如下:
essyssededddddeitthattdeeihhhaaddeahitt'sssoddisswoouurceeeessthauleawwhaiyveeeedddaabeacckkeahhinndttherrwwwoourddsssssoffdttheeyoolllddddseeihcooufhffiepbberitttiuiappllaaceeesddyyeeeeereddsdddddddddddddddddyheddeeekmiiitttwwwaassihhrreeffpuuuttttileddettoooobbeehhandeteciannddtsttrickkgguettdehhindthhheaddeedrlllonnggaddddeawbrrookkkeachinnghistsiineearreellhyyttoafficccoourrseeddtthroughhthotewssseeawwoourdddssssdddsssssssddyyyeddhwwwiithhhdeetaad'aarrkkeee'sssssddsassheachsacrreitessstooffesstdaaphooollleeenehhanddthedaachasstteeddiisgaaaddeeeddddedddseedededddddhhedddddddddaabhuttttddddabbyyyeittheesattiimmeeeeoantetooreeachheedddttlleaineed''ssddohhhoolllllehoowwhheddddiiittttwwwassstha''aaqquuiiddeedhetteeddedddawwwelllehudccoondddddouccttddadhedddeallitttlleessdissttreeatheghheedddssa
仍能隐约读出原文,但有一个问题在于,那些被判定为空的帧(即最大值在那5维),在排除这五维之后剩下的最大probability,对应的字母,有较大的实际意义吗?
留下m小点、m大点置零:
留下m大点、m小点置零:
初听会觉得结果正了,但是看练出的m,
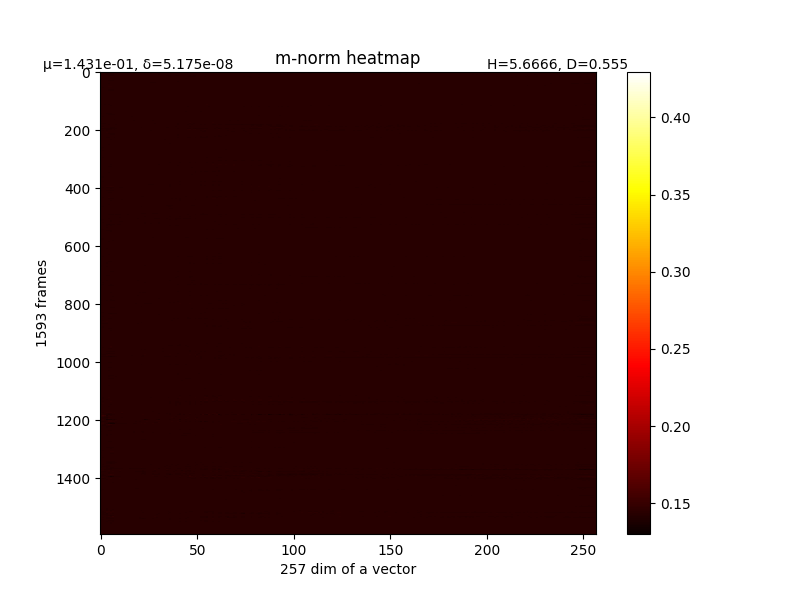
整个m的方差格外小,说明几乎还没有分化开来
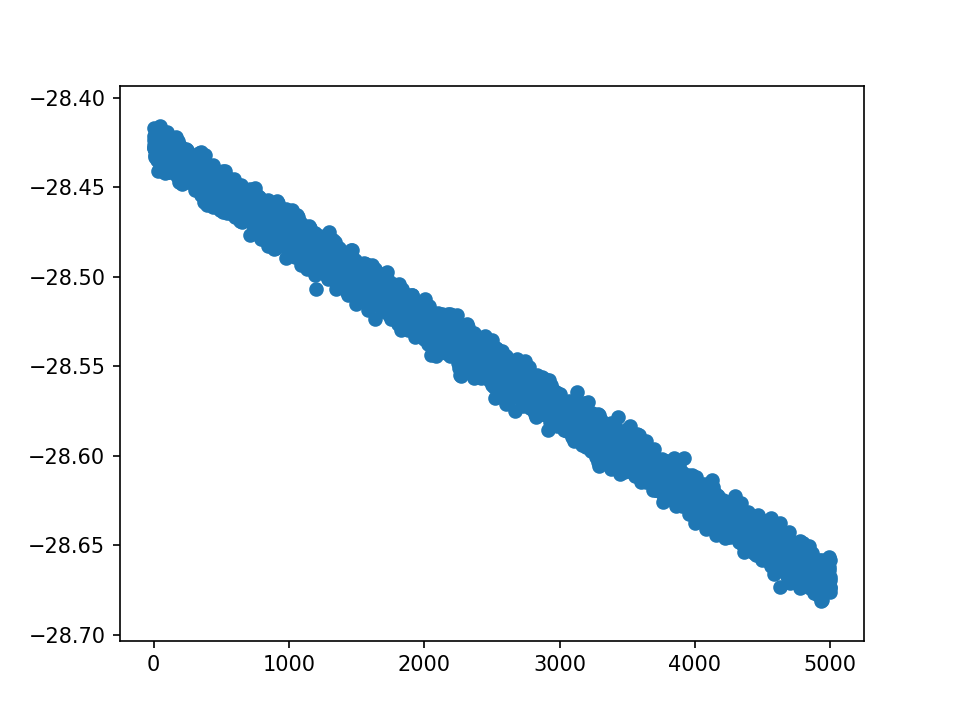
从loss来看,仍在下降中,
而声音能明显分离则是在取50%阈值操作时,m有大量值相同,造成实际点的个数并不是一半一半,
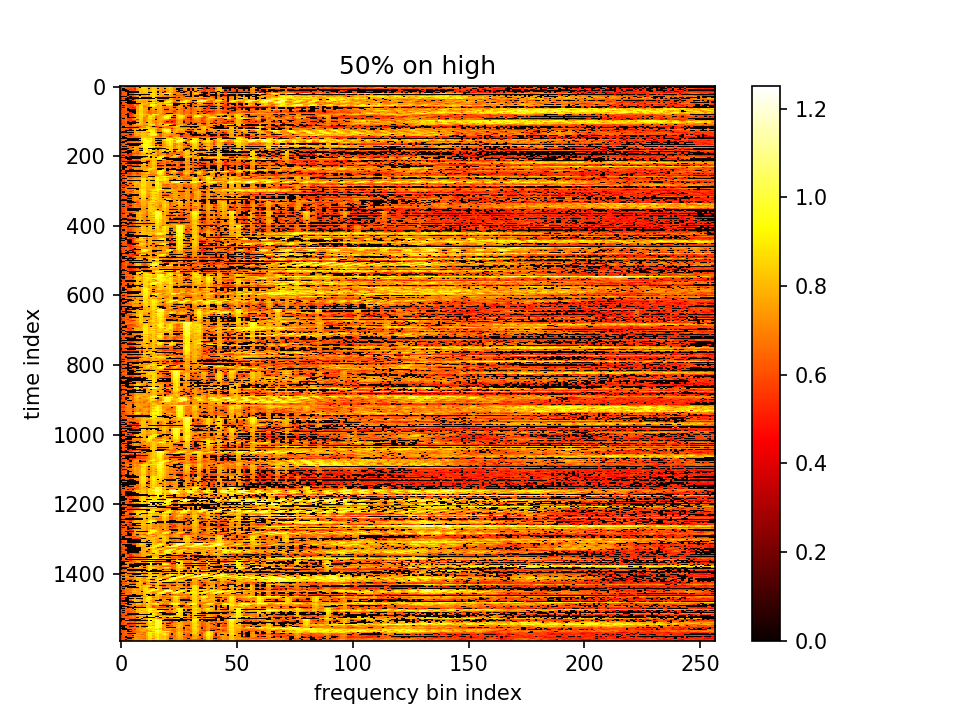
目前的训练参数:lr=0.001, m_initial=0.1, lambda=10, epoch=5000